搜索到
2
篇与
ai
的结果
-
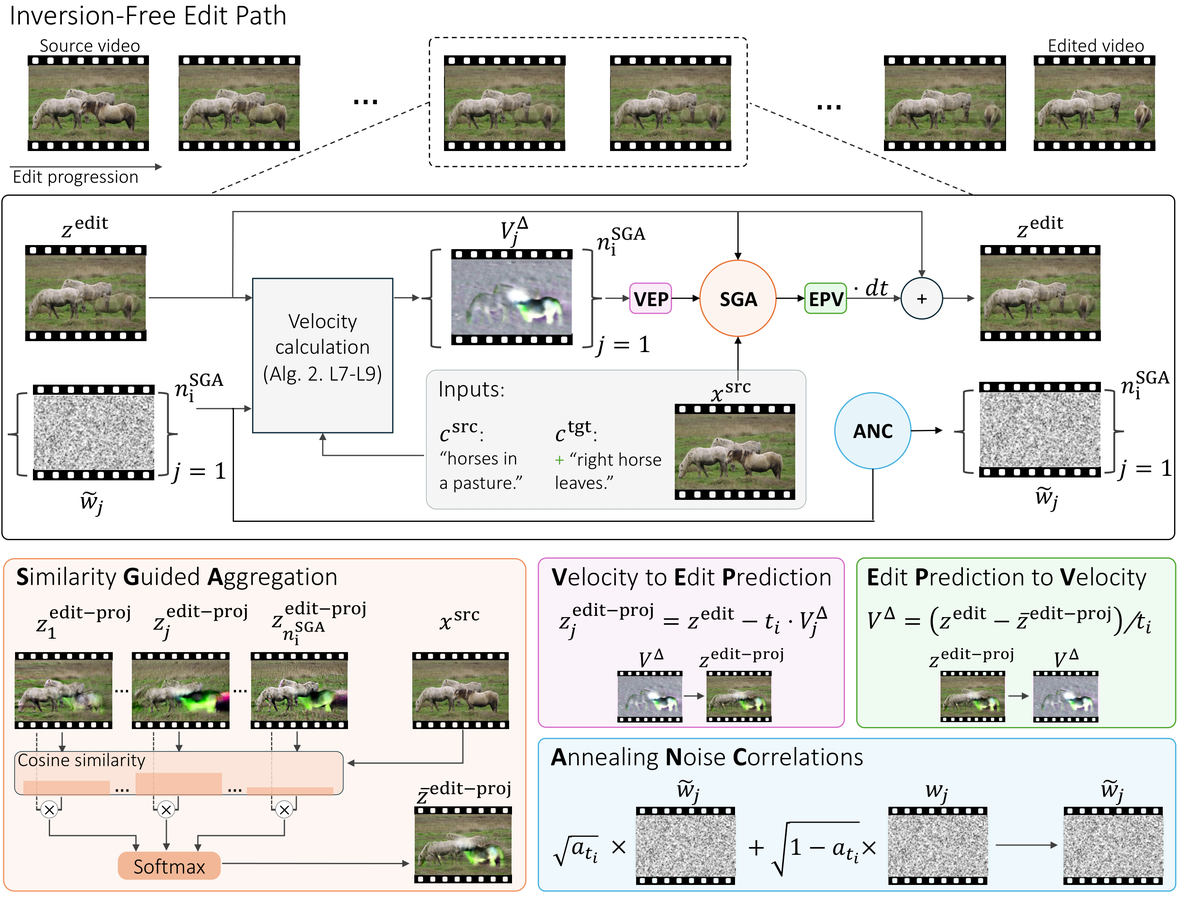
 AIGC 每日速读|2026-03-20|DynaEdit|Identity as Presence|Few-Step Diffusion| [ { "@context": "https://schema.org", "@type": "TechArticle", "headline": "AIGC 每日速读|2026-03-20|DynaEdit|Identity as Presence|Few-Step Diffusion|", "description": "AIGC领域9篇最新论文速读,重点解读TransText** (TransText: Transparency Aware Image-to-Video Typography Animation)、Edit Spillover** (Edit Spillover as a Probe: Do Image Edit...", "url": "https://jefxiong.cn/index.php/archives/aigc-daily-papers-20260320.html", "image": "https://jefxiong-1304293246.cos.ap-shenzhen-fsi.myqcloud.com/blog_cover/WechatIMG72.jpeg", "datePublished": "2026-03-20T09:00:00+08:00", "dateModified": "2026-03-20T09:00:00+08:00", "author": { "@type": "Person", "name": "人工智能炼丹师", "url": "https://jefxiong.cn/index.php/about-me.html" }, "publisher": { "@type": "Organization", "name": "人工智能炼丹师", "url": "https://jefxiong.cn", "logo": { "@type": "ImageObject", "url": "https://jefxiong-1304293246.cos.ap-shenzhen-fsi.myqcloud.com/blog_cover/WechatIMG72.jpeg" } }, "mainEntityOfPage": { "@type": "WebPage", "@id": "https://jefxiong.cn/index.php/archives/aigc-daily-papers-20260320.html" }, "keywords": [ "dit", "视频生成", "视频编辑", "ai", "diffusion", "aigc", "预训练", "Video", "generation", "多模态" ], "articleSection": "AIGC", "inLanguage": "zh-CN", "citation": [ { "@type": "ScholarlyArticle", "name": "TransText** (TransText: Transparency Aware Image-to-Video Typography Animation)" }, { "@type": "ScholarlyArticle", "name": "Edit Spillover** (Edit Spillover as a Probe: Do Image Editing Models Implicitly Understand World Relations?)" }, { "@type": "ScholarlyArticle", "name": "StereoWorld** (Stereo World Model: Camera-Guided Stereo Video Generation)" }, { "@type": "ScholarlyArticle", "name": "AC-Foley** (AC-Foley: Reference-Audio-Guided Video-to-Audio Synthesis with Acoustic Transfer" }, { "@type": "ScholarlyArticle", "name": "MosaicMem** (MosaicMem: Hybrid Spatial Memory for Controllable Video World Models)" }, { "@type": "ScholarlyArticle", "name": "Inbetweening** (Anchoring and Rescaling Attention for Semantically Coherent Inbetweening" }, { "@type": "ScholarlyArticle", "name": "LaDe** (LaDe: Unified Multi-Layered Graphic Media Generation and Decomposition)" }, { "@type": "ScholarlyArticle", "name": "Text Embedding Steering** (The Unreasonable Effectiveness of Text Embedding Interpolation for Continuous Image Steering)" }, { "@type": "ScholarlyArticle", "name": "STAS** (Steering Video Diffusion Transformers with Massive Activations)" } ] }, { "@context": "https://schema.org", "@type": "BreadcrumbList", "itemListElement": [ { "@type": "ListItem", "position": 1, "name": "首页", "item": "https://jefxiong.cn" }, { "@type": "ListItem", "position": 2, "name": "AIGC", "item": "https://jefxiong.cn/index.php/category/AIGC/" }, { "@type": "ListItem", "position": 3, "name": "AIGC 每日速读|2026-03-20|DynaEdit|Identity as Presence|Few-Step Diffusion|", "item": "https://jefxiong.cn/index.php/archives/aigc-daily-papers-20260320.html" } ] } ] AIGC 视觉生成领域 · 每日论文解读 (2026-03-20) 人工智能炼丹师 整理 | 共 12 篇论文 | 重点深度解读 3 篇 今日核心看点 DynaEdit: 无训练视频动态编辑 身份音视频联合个性化生成 实例感知扩散加速采样 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 12 篇,重点解读 3 篇。 方向分布: 视频编辑 / 无训练方法 — 3 篇 音视频联合 / 个性化生成 — 2 篇 采样加速 / 效率优化 — 2 篇 视频生成 / 世界模型 — 3 篇 生成评估与设计 — 2 篇 共计 12 篇,重点解读 3 篇 重点论文深度解读 1. DynaEdit: Versatile Editing of Video Content, Actions, and Dynamics without Training 无训练多功能视频编辑 | arXiv:2603.17989 关键词: 视频编辑, 无训练, 动作修改, 动态编辑, Flow Model 研究动机 受控视频生成取得了显著进展,但在编辑真实视频中的动作、动态事件或插入会影响场景中其他物体行为的内容方面仍然是巨大挑战。现有训练方法因缺乏合适的训练数据而难以处理复杂编辑,无训练方法则仅限于结构和运动保留的简单编辑,不支持修改运动或物体交互。 方法原理 提出 DynaEdit,利用预训练的 Text-to-Video Flow Model 实现通用视频编辑: 采用 inversion-free 方法(不干预模型内部),完全模型无关 识别并解决了两个关键问题:低频失配(场景整体色调/亮度偏移)和高频抖动(帧间闪烁) 引入新机制克服这些现象:低频校准恢复场景一致性,高频平滑消除闪烁 支持修改动作、插入与场景交互的物体、引入全局效果等复杂编辑 核心创新 首个支持动作修改和动态交互编辑的无训练视频编辑方法 深入分析了 inversion-free 编辑的两大失败模式(低频失配+高频抖动)并提出针对性解决方案 完全模型无关,可直接应用于任何 Text-to-Video Flow Model 在复杂编辑任务上首次达到 SOTA 实验结果 在动作修改、物体插入交互、全局效果添加等复杂编辑任务上达到 SOTA 大量实验验证了编辑的时间一致性和视觉质量 支持基于文本的精细化视频编辑控制 方法流程 输入视频+编辑Prompt — 原始视频 + 目标编辑指令 Inversion-Free 处理 — 不做反转,不干预模型 保持模型无关性 低频校准 — 修正色调/亮度偏移 恢复场景一致性 高频平滑 — 消除帧间闪烁 保持时间连贯 Flow Model 采样 — 预训练 T2V 模型 生成编辑结果 编辑输出 — 动作修改/物体插入 /全局效果 技术脉络 核心问题: 视频编辑中动作修改和动态交互编辑缺乏无训练解决方案 前序工作及局限: TokenFlow (2023):训练无关但仅支持外观编辑,不能修改运动 FateZero (2023):注意力操控但受限于结构保留编辑 Pix2Video (2023):逐帧编辑但缺乏时间一致性保障 Rave (2024):随机化注意力但不支持动态交互 与前序工作的本质区别: 首次通过 inversion-free 方法实现动作修改和物体交互编辑,深入分析并解决了低频失配和高频抖动两个核心问题 技术演进定位: 范式扩展——将无训练视频编辑从外观编辑推广到动作和动态编辑 可能的后续方向: 更长视频的动态编辑 物理一致性约束下的交互编辑 与 LLM 结合的多轮交互式编辑 批判性点评 实验评估: 定性实验涵盖动作修改、物体插入和全局效果三类复杂编辑。但缺少与 Fairy (2024) 等最新训练方法的定量对比。低频校准和高频平滑的消融实验有说服力。 新颖性: 从 failure mode 出发的方法设计思路清晰有力。inversion-free 加 frequency-aware correction 的组合是新颖的。创新性评分:★★★★☆ 可复现性: 方法描述清晰,依赖预训练 T2V Flow Model 即可运行。但不同 Flow Model 上的泛化性需要更多验证。 影响力: 影响力评分 4/5 — 将无训练编辑扩展到动态场景是重要突破,实用价值高。但受限于 T2V 模型的基础生成质量。 2. Identity as Presence: Appearance and Voice Personalized Joint Audio-Video Generation 身份感知联合音视频个性化生成 | arXiv:2603.17889 关键词: 音视频联合生成, 身份保持, 外观+声音, 多主体, 个性化 研究动机 近期进展已展示了将真实个体合成到生成视频中的能力,但一个公开可用的、支持对面部外观和声音音色进行细粒度控制的多身份框架仍然缺失。核心挑战包括:配对的身份音视频数据稀缺、多模态之间的差异性、以及多主体场景下的身份串扰问题。 方法原理 提出统一可扩展的身份感知联合音视频生成框架: 数据策划管线:自动提取带配对标注的身份信息(音频+视觉模态),覆盖单人到多人交互等多种场景 灵活可扩展的身份注入机制:面部外观和声音音色同时作为身份控制信号 多阶段训练策略:针对模态差异设计,加速收敛并强化跨模态一致性 支持单人和多人场景的个性化生成 核心创新 首个同时支持外观和声音个性化控制的联合音视频生成框架 可扩展的身份注入机制,支持从单人到多人的灵活场景 自动化数据策划管线,解决身份配对数据稀缺问题 多阶段训练策略有效缓解音视频模态差异 实验结果 在身份保持度、音视频一致性、生成质量等多维度上均优于现有方法 支持多主体交互场景的高保真个性化生成 项目页面已公开,展示了丰富的定性结果 方法流程 身份输入 — 面部参考图 + 声音样本 定义目标身份 数据策划 — 自动提取配对标注 单人/多人场景 身份注入 — 外观+声音双通道 身份控制信号 多阶段训练 — 渐进式跨模态 一致性强化 联合生成 — 音频+视频同步 身份保持输出 技术脉络 核心问题: 缺乏同时控制外观和声音的多身份联合音视频生成框架 前序工作及局限: IP-Adapter (2023):图像参考注入但不支持音频身份 DreamTalk (2024):语音驱动但不支持外观个性化 OmniForcing (2025):实时音视频但缺乏身份定制能力 MM-Diffusion (2023):联合音视频但不支持身份控制 与前序工作的本质区别: 首次将面部外观和声音音色统一为身份控制信号,支持单人和多人场景的可扩展注入 技术演进定位: 能力整合——在联合音视频生成上叠加身份个性化控制,向 AI 虚拟人迈进 可能的后续方向: 实时身份保持的流式音视频生成 身份风格迁移和混合 多语言多口音的声音身份控制 批判性点评 实验评估: 覆盖单人和多人场景,定性结果丰富。但缺少与 StoryDiffusion、ConsistentID 等方法的系统定量对比。数据策划管线的错误率影响待评估。 新颖性: 外观+声音双通道身份控制的统一框架具有开创性。多阶段训练策略设计合理。创新性评分:★★★★☆ 可复现性: 框架描述完整,但数据策划管线的具体实现细节和多人场景的身份隔离策略需要更多信息。项目页面已公开。 影响力: 影响力评分 4/5 — 为 AI 虚拟人和个性化内容创作提供了新能力。但实际部署的身份一致性稳定性仍需验证。 3. Few-Step Diffusion Sampling Through Instance-Aware Discretizations 实例感知离散化加速扩散采样 | arXiv:2603.17671 关键词: 扩散加速, 离散化策略, 实例感知, 少步采样, Flow Matching 研究动机 扩散模型和 Flow Matching 模型通过模拟 ODE/SDE 路径生成高保真数据,但采样速度受制于离散化步数。现有离散化策略——无论是手工设计还是基于优化的——都在所有样本上强制执行全局共享的时间步调度。这种统一处理忽略了生成过程中特定实例的复杂性差异,限制了性能。 方法原理 提出实例感知离散化框架: 通过合成数据上的对照实验揭示:特定实例动态下全局调度的次优性 学习根据输入依赖的先验来调整时间步分配 将基于梯度的离散化搜索扩展到条件生成设置 以微小的调优成本和可忽略的推理开销实现质量提升 核心创新 首次提出实例感知的自适应离散化框架,打破全局统一时间步的限制 理论分析和合成实验揭示了全局调度的次优性根源 框架通用性强,适用于像素空间扩散、潜在空间图像和视频 Flow Matching 调优成本极低(相比训练),推理开销可忽略 实验结果 合成数据、像素空间扩散、潜在空间图像 Flow Matching、视频 Flow Matching 多场景验证 在相同步数下一致性地改善生成质量 调优成本仅为训练成本的极小比例,推理时开销可忽略 方法流程 输入条件 c — 文本/图像条件 决定生成复杂度 实例先验估计 — 根据 c 预测 最优时间步分配 自适应离散化 — 简单实例: 少步粗调 复杂实例: 多步精调 ODE/SDE 求解 — 按实例最优调度 执行采样路径 高质量输出 — 相同总步数下 质量显著提升 技术脉络 核心问题: 现有离散化策略对所有样本使用统一时间步调度,忽略实例间复杂度差异 前序工作及局限: DDIM (Song 2020):均匀步长离散化,全局统一 DPM-Solver (Lu 2022):高阶 ODE 求解器但固定调度 AYS (Sabour 2024):优化离散化但样本无关 Align Your Steps (2024):基于搜索的最优调度但仍全局共享 与前序工作的本质区别: 从样本无关到样本感知,根据输入条件动态分配时间步,首次将离散化个性化 技术演进定位: 正交改进——与求解器设计正交,可叠加在任何采样方法上,是通用的性能增强组件 可能的后续方向: 与自适应步长 ODE 求解器结合 学习端到端的生成路径而非离散化点 视频生成中的时空自适应调度 批判性点评 实验评估: 合成数据、像素扩散、潜在空间图像和视频四个设定全面验证。与 DDIM、DPM-Solver、AYS 的对比合理。但在大型模型(FLUX、CogVideoX)上的效果待验证。 新颖性: 实例感知的动机清晰,理论分析扎实。但输入先验的学习方式相对简单。创新性评分:★★★☆☆ 可复现性: 梯度搜索和先验网络的训练细节完整。调优成本低是一大优势。实现门槛不高。 影响力: 影响力评分 3/5 — 作为正交改进可叠加在各种采样方法上,但单独的质量提升幅度有限。 批判性点评精选 1. DynaEdit 开启视频编辑新纪元:从外观到动态 DynaEdit 将无训练视频编辑从简单的外观变换推向了动作修改和物体交互编辑的全新领域。它发现并解决的低频失配和高频抖动问题,不仅适用于当前方法,更可能成为未来所有 inversion-free 编辑方法的必要组件。这标志着视频编辑正在从'改外观'向'改行为'跨越。 2. 身份个性化:多模态生成的下一个前沿 Identity as Presence 同时控制外观和声音的方案,让联合音视频生成不再是'匿名的'内容合成,而是真正的个性化内容创作。从技术上,多阶段训练策略巧妙处理了音频和视觉模态之间巨大的表征差异。从应用上,这为虚拟人、个性化视频消息、AI 配音等场景打开了大门。 3. 实例感知:一个被忽视的正交优化维度 Few-Step Discretization 的核心洞察简洁而有力:不同生成实例的'难度'不同,为什么要用相同的采样调度?这个问题如此显而易见,却直到现在才被正式提出。作为正交改进,它可以与任何采样方法叠加——DPM-Solver++、DDIM、Euler 都能受益。虽然单独提升有限,但作为'免费午餐',没有理由不用。 其余论文 · 贡献与效果总结 # 论文 关键词 主要贡献 效果 1 TransText (TransText: Transparency Aware Image-to-Video Typography Animation) 排版动画 · I2V · Alpha通道 · 透明度建模 首个将 I2V 模型适配为图层感知文字动画的方法,Alpha-as-RGB 范式在不修改预训练生成流形的前提下联合建模外观与透明度 显著优于基线,生成连贯高保真的透明动画效果,支持多样精细的排版动画 2 Edit Spillover (Edit Spillover as a Probe: Do Image Editing Models Implicitly Understand World Relations?) 编辑溢出 · 世界知识 · 编辑评估 · Benchmark 将编辑溢出现象重新定义为探查图像编辑模型世界知识的探针,提出 EditSpilloverBench 基准和自动检测分类流水线 揭示语义溢出反映真正的世界理解(占比40-58%恒定),不同模型编辑控制与世界理解存在权衡 3 StereoWorld (Stereo World Model: Camera-Guided Stereo Video Generation) 立体视频 · VR渲染 · 相机控制 · 极线先验 端到端立体视频生成模型,统一相机帧 RoPE + 立体感知注意力分解,利用极线先验降低计算量 立体一致性和视差准确性优于单目后转换,生成速度 3x+,支持 VR 渲染和具身学习 4 AC-Foley (AC-Foley: Reference-Audio-Guided Video-to-Audio Synthesis with Acoustic Transfer ICLR 2026) 视频转音频 · 参考音频 · 音色迁移 · ICLR 2026 音频条件 V2A 模型,直接用参考音频实现精细的声音控制,绕过文本描述的语义模糊性,支持音色迁移和零样本生成 5 MosaicMem (MosaicMem: Hybrid Spatial Memory for Controllable Video World Models) 视频世界模型 · 空间记忆 · 可控生成 · 3D提升 混合空间记忆机制:将 patch 提升到 3D 进行可靠定位和目标检索,同时利用模型原生条件生成保持一致性 姿态遵循性优于隐式记忆,动态建模能力强于显式基线,支持分钟级导航和场景编辑 6 Inbetweening (Anchoring and Rescaling Attention for Semantically Coherent Inbetweening CVPR 2026) 中间帧生成 · 注意力锚定 · RoPE · CVPR 2026 关键帧锚定注意力偏置 + 重缩放时间 RoPE 实现语义一致的中间帧生成,无需额外训练 7 LaDe (LaDe: Unified Multi-Layered Graphic Media Generation and Decomposition) 图层设计 · 多任务统一 · RGBA VAE · 图形设计 潜在扩散框架 + LLM prompt 扩展 + 4D RoPE + RGBA VAE,统一文本到图像、文本到图层和设计分解三个任务 文本到图层任务上文本-图层对齐度优于 Qwen-Image-Layered(GPT-4o mini + Qwen3-VL 评估) 8 Text Embedding Steering (The Unreasonable Effectiveness of Text Embedding Interpolation for Continuous Image Steering) 连续编辑 · Steering Vector · 训练无关 · 跨模态 训练无关框架:LLM 自动构建去偏对比 prompt 对,文本嵌入空间 steering vector + 弹性范围搜索实现连续可控编辑 效果可比肩训练方法,优于其他训练无关方案,自然支持图像和视频两种模态 9 STAS (Steering Video Diffusion Transformers with Massive Activations) 视频DiT · Massive Activations · 自引导 · 零开销 发现视频 DiT 中 Massive Activations 的结构化时间层次:首帧最大→潜在帧边界→帧内 token 递减,据此提出 STAS 自引导方法 不同 T2V 模型上一致提升视频质量和时间连贯性,计算开销可忽略 趋势观察 无训练视频编辑突破 — DynaEdit 首次实现无训练的动作修改和动态交互编辑,Inbetweening 无需额外训练实现语义一致的中间帧生成 身份感知多模态生成 — Identity as Presence 同时控制外观和声音进行音视频联合生成,StereoWorld 实现端到端立体视频 采样效率精细化优化 — 实例感知离散化打破全局统一时间步限制,STAS 用 Massive Activations 零开销提升视频 DiT 质量 音频生成深化 — AC-Foley 用参考音频实现精细 V2A 控制,Identity as Presence 将声音身份引入视频生成 生成模型评估与理解 — Edit Spillover 用编辑溢出探查模型世界知识,Text Embedding Steering 揭示嵌入空间的连续可控性 人工智能炼丹师 整理 | 2026-03-20
AIGC 每日速读|2026-03-20|DynaEdit|Identity as Presence|Few-Step Diffusion| [ { "@context": "https://schema.org", "@type": "TechArticle", "headline": "AIGC 每日速读|2026-03-20|DynaEdit|Identity as Presence|Few-Step Diffusion|", "description": "AIGC领域9篇最新论文速读,重点解读TransText** (TransText: Transparency Aware Image-to-Video Typography Animation)、Edit Spillover** (Edit Spillover as a Probe: Do Image Edit...", "url": "https://jefxiong.cn/index.php/archives/aigc-daily-papers-20260320.html", "image": "https://jefxiong-1304293246.cos.ap-shenzhen-fsi.myqcloud.com/blog_cover/WechatIMG72.jpeg", "datePublished": "2026-03-20T09:00:00+08:00", "dateModified": "2026-03-20T09:00:00+08:00", "author": { "@type": "Person", "name": "人工智能炼丹师", "url": "https://jefxiong.cn/index.php/about-me.html" }, "publisher": { "@type": "Organization", "name": "人工智能炼丹师", "url": "https://jefxiong.cn", "logo": { "@type": "ImageObject", "url": "https://jefxiong-1304293246.cos.ap-shenzhen-fsi.myqcloud.com/blog_cover/WechatIMG72.jpeg" } }, "mainEntityOfPage": { "@type": "WebPage", "@id": "https://jefxiong.cn/index.php/archives/aigc-daily-papers-20260320.html" }, "keywords": [ "dit", "视频生成", "视频编辑", "ai", "diffusion", "aigc", "预训练", "Video", "generation", "多模态" ], "articleSection": "AIGC", "inLanguage": "zh-CN", "citation": [ { "@type": "ScholarlyArticle", "name": "TransText** (TransText: Transparency Aware Image-to-Video Typography Animation)" }, { "@type": "ScholarlyArticle", "name": "Edit Spillover** (Edit Spillover as a Probe: Do Image Editing Models Implicitly Understand World Relations?)" }, { "@type": "ScholarlyArticle", "name": "StereoWorld** (Stereo World Model: Camera-Guided Stereo Video Generation)" }, { "@type": "ScholarlyArticle", "name": "AC-Foley** (AC-Foley: Reference-Audio-Guided Video-to-Audio Synthesis with Acoustic Transfer" }, { "@type": "ScholarlyArticle", "name": "MosaicMem** (MosaicMem: Hybrid Spatial Memory for Controllable Video World Models)" }, { "@type": "ScholarlyArticle", "name": "Inbetweening** (Anchoring and Rescaling Attention for Semantically Coherent Inbetweening" }, { "@type": "ScholarlyArticle", "name": "LaDe** (LaDe: Unified Multi-Layered Graphic Media Generation and Decomposition)" }, { "@type": "ScholarlyArticle", "name": "Text Embedding Steering** (The Unreasonable Effectiveness of Text Embedding Interpolation for Continuous Image Steering)" }, { "@type": "ScholarlyArticle", "name": "STAS** (Steering Video Diffusion Transformers with Massive Activations)" } ] }, { "@context": "https://schema.org", "@type": "BreadcrumbList", "itemListElement": [ { "@type": "ListItem", "position": 1, "name": "首页", "item": "https://jefxiong.cn" }, { "@type": "ListItem", "position": 2, "name": "AIGC", "item": "https://jefxiong.cn/index.php/category/AIGC/" }, { "@type": "ListItem", "position": 3, "name": "AIGC 每日速读|2026-03-20|DynaEdit|Identity as Presence|Few-Step Diffusion|", "item": "https://jefxiong.cn/index.php/archives/aigc-daily-papers-20260320.html" } ] } ] AIGC 视觉生成领域 · 每日论文解读 (2026-03-20) 人工智能炼丹师 整理 | 共 12 篇论文 | 重点深度解读 3 篇 今日核心看点 DynaEdit: 无训练视频动态编辑 身份音视频联合个性化生成 实例感知扩散加速采样 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 12 篇,重点解读 3 篇。 方向分布: 视频编辑 / 无训练方法 — 3 篇 音视频联合 / 个性化生成 — 2 篇 采样加速 / 效率优化 — 2 篇 视频生成 / 世界模型 — 3 篇 生成评估与设计 — 2 篇 共计 12 篇,重点解读 3 篇 重点论文深度解读 1. DynaEdit: Versatile Editing of Video Content, Actions, and Dynamics without Training 无训练多功能视频编辑 | arXiv:2603.17989 关键词: 视频编辑, 无训练, 动作修改, 动态编辑, Flow Model 研究动机 受控视频生成取得了显著进展,但在编辑真实视频中的动作、动态事件或插入会影响场景中其他物体行为的内容方面仍然是巨大挑战。现有训练方法因缺乏合适的训练数据而难以处理复杂编辑,无训练方法则仅限于结构和运动保留的简单编辑,不支持修改运动或物体交互。 方法原理 提出 DynaEdit,利用预训练的 Text-to-Video Flow Model 实现通用视频编辑: 采用 inversion-free 方法(不干预模型内部),完全模型无关 识别并解决了两个关键问题:低频失配(场景整体色调/亮度偏移)和高频抖动(帧间闪烁) 引入新机制克服这些现象:低频校准恢复场景一致性,高频平滑消除闪烁 支持修改动作、插入与场景交互的物体、引入全局效果等复杂编辑 核心创新 首个支持动作修改和动态交互编辑的无训练视频编辑方法 深入分析了 inversion-free 编辑的两大失败模式(低频失配+高频抖动)并提出针对性解决方案 完全模型无关,可直接应用于任何 Text-to-Video Flow Model 在复杂编辑任务上首次达到 SOTA 实验结果 在动作修改、物体插入交互、全局效果添加等复杂编辑任务上达到 SOTA 大量实验验证了编辑的时间一致性和视觉质量 支持基于文本的精细化视频编辑控制 方法流程 输入视频+编辑Prompt — 原始视频 + 目标编辑指令 Inversion-Free 处理 — 不做反转,不干预模型 保持模型无关性 低频校准 — 修正色调/亮度偏移 恢复场景一致性 高频平滑 — 消除帧间闪烁 保持时间连贯 Flow Model 采样 — 预训练 T2V 模型 生成编辑结果 编辑输出 — 动作修改/物体插入 /全局效果 技术脉络 核心问题: 视频编辑中动作修改和动态交互编辑缺乏无训练解决方案 前序工作及局限: TokenFlow (2023):训练无关但仅支持外观编辑,不能修改运动 FateZero (2023):注意力操控但受限于结构保留编辑 Pix2Video (2023):逐帧编辑但缺乏时间一致性保障 Rave (2024):随机化注意力但不支持动态交互 与前序工作的本质区别: 首次通过 inversion-free 方法实现动作修改和物体交互编辑,深入分析并解决了低频失配和高频抖动两个核心问题 技术演进定位: 范式扩展——将无训练视频编辑从外观编辑推广到动作和动态编辑 可能的后续方向: 更长视频的动态编辑 物理一致性约束下的交互编辑 与 LLM 结合的多轮交互式编辑 批判性点评 实验评估: 定性实验涵盖动作修改、物体插入和全局效果三类复杂编辑。但缺少与 Fairy (2024) 等最新训练方法的定量对比。低频校准和高频平滑的消融实验有说服力。 新颖性: 从 failure mode 出发的方法设计思路清晰有力。inversion-free 加 frequency-aware correction 的组合是新颖的。创新性评分:★★★★☆ 可复现性: 方法描述清晰,依赖预训练 T2V Flow Model 即可运行。但不同 Flow Model 上的泛化性需要更多验证。 影响力: 影响力评分 4/5 — 将无训练编辑扩展到动态场景是重要突破,实用价值高。但受限于 T2V 模型的基础生成质量。 2. Identity as Presence: Appearance and Voice Personalized Joint Audio-Video Generation 身份感知联合音视频个性化生成 | arXiv:2603.17889 关键词: 音视频联合生成, 身份保持, 外观+声音, 多主体, 个性化 研究动机 近期进展已展示了将真实个体合成到生成视频中的能力,但一个公开可用的、支持对面部外观和声音音色进行细粒度控制的多身份框架仍然缺失。核心挑战包括:配对的身份音视频数据稀缺、多模态之间的差异性、以及多主体场景下的身份串扰问题。 方法原理 提出统一可扩展的身份感知联合音视频生成框架: 数据策划管线:自动提取带配对标注的身份信息(音频+视觉模态),覆盖单人到多人交互等多种场景 灵活可扩展的身份注入机制:面部外观和声音音色同时作为身份控制信号 多阶段训练策略:针对模态差异设计,加速收敛并强化跨模态一致性 支持单人和多人场景的个性化生成 核心创新 首个同时支持外观和声音个性化控制的联合音视频生成框架 可扩展的身份注入机制,支持从单人到多人的灵活场景 自动化数据策划管线,解决身份配对数据稀缺问题 多阶段训练策略有效缓解音视频模态差异 实验结果 在身份保持度、音视频一致性、生成质量等多维度上均优于现有方法 支持多主体交互场景的高保真个性化生成 项目页面已公开,展示了丰富的定性结果 方法流程 身份输入 — 面部参考图 + 声音样本 定义目标身份 数据策划 — 自动提取配对标注 单人/多人场景 身份注入 — 外观+声音双通道 身份控制信号 多阶段训练 — 渐进式跨模态 一致性强化 联合生成 — 音频+视频同步 身份保持输出 技术脉络 核心问题: 缺乏同时控制外观和声音的多身份联合音视频生成框架 前序工作及局限: IP-Adapter (2023):图像参考注入但不支持音频身份 DreamTalk (2024):语音驱动但不支持外观个性化 OmniForcing (2025):实时音视频但缺乏身份定制能力 MM-Diffusion (2023):联合音视频但不支持身份控制 与前序工作的本质区别: 首次将面部外观和声音音色统一为身份控制信号,支持单人和多人场景的可扩展注入 技术演进定位: 能力整合——在联合音视频生成上叠加身份个性化控制,向 AI 虚拟人迈进 可能的后续方向: 实时身份保持的流式音视频生成 身份风格迁移和混合 多语言多口音的声音身份控制 批判性点评 实验评估: 覆盖单人和多人场景,定性结果丰富。但缺少与 StoryDiffusion、ConsistentID 等方法的系统定量对比。数据策划管线的错误率影响待评估。 新颖性: 外观+声音双通道身份控制的统一框架具有开创性。多阶段训练策略设计合理。创新性评分:★★★★☆ 可复现性: 框架描述完整,但数据策划管线的具体实现细节和多人场景的身份隔离策略需要更多信息。项目页面已公开。 影响力: 影响力评分 4/5 — 为 AI 虚拟人和个性化内容创作提供了新能力。但实际部署的身份一致性稳定性仍需验证。 3. Few-Step Diffusion Sampling Through Instance-Aware Discretizations 实例感知离散化加速扩散采样 | arXiv:2603.17671 关键词: 扩散加速, 离散化策略, 实例感知, 少步采样, Flow Matching 研究动机 扩散模型和 Flow Matching 模型通过模拟 ODE/SDE 路径生成高保真数据,但采样速度受制于离散化步数。现有离散化策略——无论是手工设计还是基于优化的——都在所有样本上强制执行全局共享的时间步调度。这种统一处理忽略了生成过程中特定实例的复杂性差异,限制了性能。 方法原理 提出实例感知离散化框架: 通过合成数据上的对照实验揭示:特定实例动态下全局调度的次优性 学习根据输入依赖的先验来调整时间步分配 将基于梯度的离散化搜索扩展到条件生成设置 以微小的调优成本和可忽略的推理开销实现质量提升 核心创新 首次提出实例感知的自适应离散化框架,打破全局统一时间步的限制 理论分析和合成实验揭示了全局调度的次优性根源 框架通用性强,适用于像素空间扩散、潜在空间图像和视频 Flow Matching 调优成本极低(相比训练),推理开销可忽略 实验结果 合成数据、像素空间扩散、潜在空间图像 Flow Matching、视频 Flow Matching 多场景验证 在相同步数下一致性地改善生成质量 调优成本仅为训练成本的极小比例,推理时开销可忽略 方法流程 输入条件 c — 文本/图像条件 决定生成复杂度 实例先验估计 — 根据 c 预测 最优时间步分配 自适应离散化 — 简单实例: 少步粗调 复杂实例: 多步精调 ODE/SDE 求解 — 按实例最优调度 执行采样路径 高质量输出 — 相同总步数下 质量显著提升 技术脉络 核心问题: 现有离散化策略对所有样本使用统一时间步调度,忽略实例间复杂度差异 前序工作及局限: DDIM (Song 2020):均匀步长离散化,全局统一 DPM-Solver (Lu 2022):高阶 ODE 求解器但固定调度 AYS (Sabour 2024):优化离散化但样本无关 Align Your Steps (2024):基于搜索的最优调度但仍全局共享 与前序工作的本质区别: 从样本无关到样本感知,根据输入条件动态分配时间步,首次将离散化个性化 技术演进定位: 正交改进——与求解器设计正交,可叠加在任何采样方法上,是通用的性能增强组件 可能的后续方向: 与自适应步长 ODE 求解器结合 学习端到端的生成路径而非离散化点 视频生成中的时空自适应调度 批判性点评 实验评估: 合成数据、像素扩散、潜在空间图像和视频四个设定全面验证。与 DDIM、DPM-Solver、AYS 的对比合理。但在大型模型(FLUX、CogVideoX)上的效果待验证。 新颖性: 实例感知的动机清晰,理论分析扎实。但输入先验的学习方式相对简单。创新性评分:★★★☆☆ 可复现性: 梯度搜索和先验网络的训练细节完整。调优成本低是一大优势。实现门槛不高。 影响力: 影响力评分 3/5 — 作为正交改进可叠加在各种采样方法上,但单独的质量提升幅度有限。 批判性点评精选 1. DynaEdit 开启视频编辑新纪元:从外观到动态 DynaEdit 将无训练视频编辑从简单的外观变换推向了动作修改和物体交互编辑的全新领域。它发现并解决的低频失配和高频抖动问题,不仅适用于当前方法,更可能成为未来所有 inversion-free 编辑方法的必要组件。这标志着视频编辑正在从'改外观'向'改行为'跨越。 2. 身份个性化:多模态生成的下一个前沿 Identity as Presence 同时控制外观和声音的方案,让联合音视频生成不再是'匿名的'内容合成,而是真正的个性化内容创作。从技术上,多阶段训练策略巧妙处理了音频和视觉模态之间巨大的表征差异。从应用上,这为虚拟人、个性化视频消息、AI 配音等场景打开了大门。 3. 实例感知:一个被忽视的正交优化维度 Few-Step Discretization 的核心洞察简洁而有力:不同生成实例的'难度'不同,为什么要用相同的采样调度?这个问题如此显而易见,却直到现在才被正式提出。作为正交改进,它可以与任何采样方法叠加——DPM-Solver++、DDIM、Euler 都能受益。虽然单独提升有限,但作为'免费午餐',没有理由不用。 其余论文 · 贡献与效果总结 # 论文 关键词 主要贡献 效果 1 TransText (TransText: Transparency Aware Image-to-Video Typography Animation) 排版动画 · I2V · Alpha通道 · 透明度建模 首个将 I2V 模型适配为图层感知文字动画的方法,Alpha-as-RGB 范式在不修改预训练生成流形的前提下联合建模外观与透明度 显著优于基线,生成连贯高保真的透明动画效果,支持多样精细的排版动画 2 Edit Spillover (Edit Spillover as a Probe: Do Image Editing Models Implicitly Understand World Relations?) 编辑溢出 · 世界知识 · 编辑评估 · Benchmark 将编辑溢出现象重新定义为探查图像编辑模型世界知识的探针,提出 EditSpilloverBench 基准和自动检测分类流水线 揭示语义溢出反映真正的世界理解(占比40-58%恒定),不同模型编辑控制与世界理解存在权衡 3 StereoWorld (Stereo World Model: Camera-Guided Stereo Video Generation) 立体视频 · VR渲染 · 相机控制 · 极线先验 端到端立体视频生成模型,统一相机帧 RoPE + 立体感知注意力分解,利用极线先验降低计算量 立体一致性和视差准确性优于单目后转换,生成速度 3x+,支持 VR 渲染和具身学习 4 AC-Foley (AC-Foley: Reference-Audio-Guided Video-to-Audio Synthesis with Acoustic Transfer ICLR 2026) 视频转音频 · 参考音频 · 音色迁移 · ICLR 2026 音频条件 V2A 模型,直接用参考音频实现精细的声音控制,绕过文本描述的语义模糊性,支持音色迁移和零样本生成 5 MosaicMem (MosaicMem: Hybrid Spatial Memory for Controllable Video World Models) 视频世界模型 · 空间记忆 · 可控生成 · 3D提升 混合空间记忆机制:将 patch 提升到 3D 进行可靠定位和目标检索,同时利用模型原生条件生成保持一致性 姿态遵循性优于隐式记忆,动态建模能力强于显式基线,支持分钟级导航和场景编辑 6 Inbetweening (Anchoring and Rescaling Attention for Semantically Coherent Inbetweening CVPR 2026) 中间帧生成 · 注意力锚定 · RoPE · CVPR 2026 关键帧锚定注意力偏置 + 重缩放时间 RoPE 实现语义一致的中间帧生成,无需额外训练 7 LaDe (LaDe: Unified Multi-Layered Graphic Media Generation and Decomposition) 图层设计 · 多任务统一 · RGBA VAE · 图形设计 潜在扩散框架 + LLM prompt 扩展 + 4D RoPE + RGBA VAE,统一文本到图像、文本到图层和设计分解三个任务 文本到图层任务上文本-图层对齐度优于 Qwen-Image-Layered(GPT-4o mini + Qwen3-VL 评估) 8 Text Embedding Steering (The Unreasonable Effectiveness of Text Embedding Interpolation for Continuous Image Steering) 连续编辑 · Steering Vector · 训练无关 · 跨模态 训练无关框架:LLM 自动构建去偏对比 prompt 对,文本嵌入空间 steering vector + 弹性范围搜索实现连续可控编辑 效果可比肩训练方法,优于其他训练无关方案,自然支持图像和视频两种模态 9 STAS (Steering Video Diffusion Transformers with Massive Activations) 视频DiT · Massive Activations · 自引导 · 零开销 发现视频 DiT 中 Massive Activations 的结构化时间层次:首帧最大→潜在帧边界→帧内 token 递减,据此提出 STAS 自引导方法 不同 T2V 模型上一致提升视频质量和时间连贯性,计算开销可忽略 趋势观察 无训练视频编辑突破 — DynaEdit 首次实现无训练的动作修改和动态交互编辑,Inbetweening 无需额外训练实现语义一致的中间帧生成 身份感知多模态生成 — Identity as Presence 同时控制外观和声音进行音视频联合生成,StereoWorld 实现端到端立体视频 采样效率精细化优化 — 实例感知离散化打破全局统一时间步限制,STAS 用 Massive Activations 零开销提升视频 DiT 质量 音频生成深化 — AC-Foley 用参考音频实现精细 V2A 控制,Identity as Presence 将声音身份引入视频生成 生成模型评估与理解 — Edit Spillover 用编辑溢出探查模型世界知识,Text Embedding Steering 揭示嵌入空间的连续可控性 人工智能炼丹师 整理 | 2026-03-20 -
AIGC 每日速读|2026-03-18|Tri-Prompting|Anchor Forcing|VeloEdit|COT-FM|LADR| [ { "@context": "https://schema.org", "@type": "TechArticle", "headline": "AIGC生成 每日热点论文速读@20260318", "description": "AIGC领域8篇最新论文速读,重点解读LibraGen** (Playing a Balance Game in Subject-Driven Video Generation)、NumColor** (Precise Numeric Color Control in Text-to-Image Generati...", "url": "https://jefxiong.cn/index.php/archives/aigc-daily-papers-20260318.html", "image": "https://jefxiong-1304293246.cos.ap-shenzhen-fsi.myqcloud.com/blog_cover/WechatIMG72.jpeg", "datePublished": "2026-03-18T09:00:00+08:00", "dateModified": "2026-03-18T09:00:00+08:00", "author": { "@type": "Person", "name": "人工智能炼丹师", "url": "https://jefxiong.cn/index.php/about-me.html" }, "publisher": { "@type": "Organization", "name": "人工智能炼丹师", "url": "https://jefxiong.cn", "logo": { "@type": "ImageObject", "url": "https://jefxiong-1304293246.cos.ap-shenzhen-fsi.myqcloud.com/blog_cover/WechatIMG72.jpeg" } }, "mainEntityOfPage": { "@type": "WebPage", "@id": "https://jefxiong.cn/index.php/archives/aigc-daily-papers-20260318.html" }, "keywords": [ "dit", "llm", "diffusion", "图像编辑", "视频生成", "蒸馏", "图像生成", "ai", "扩散模型", "generation" ], "articleSection": "AIGC", "inLanguage": "zh-CN", "citation": [ { "@type": "ScholarlyArticle", "name": "LibraGen** (Playing a Balance Game in Subject-Driven Video Generation)" }, { "@type": "ScholarlyArticle", "name": "NumColor** (Precise Numeric Color Control in Text-to-Image Generation)" }, { "@type": "ScholarlyArticle", "name": "EVD** (Event-Driven Video Generation)" }, { "@type": "ScholarlyArticle", "name": "FlashMotion** (Few-Step Controllable Video Generation with Trajectory Guidance (CVPR 2026))" }, { "@type": "ScholarlyArticle", "name": "GlyphPrinter** (Region-Grouped DPO for Glyph-Accurate Visual Text Rendering (CVPR 2026))" }, { "@type": "ScholarlyArticle", "name": "Spectrum Matching** (A Unified Perspective for Superior Diffusability in Latent Diffusion)" }, { "@type": "ScholarlyArticle", "name": "SERUM** (Simple Efficient Robust Unifying Marking for Diffusion Image Gen (ICLR 2026))" }, { "@type": "ScholarlyArticle", "name": "DC-Diffusion** (High-Fidelity T2I from VLM via Distribution-Conditioned Diffusion Decoding)" } ] }, { "@context": "https://schema.org", "@type": "BreadcrumbList", "itemListElement": [ { "@type": "ListItem", "position": 1, "name": "首页", "item": "https://jefxiong.cn" }, { "@type": "ListItem", "position": 2, "name": "AIGC", "item": "https://jefxiong.cn/index.php/category/AIGC/" }, { "@type": "ListItem", "position": 3, "name": "AIGC生成 每日热点论文速读@20260318", "item": "https://jefxiong.cn/index.php/archives/aigc-daily-papers-20260318.html" } ] } ] AIGC 视觉生成领域 · 每日论文解读 (2026-03-18) 人工智能炼丹师 整理 | 共 13 篇论文 | 重点深度解读 5 篇 今日核心看点 Tri-Prompting 统一控制 Anchor Forcing 流式视频 VeloEdit 速度场编辑 COT-FM 最优传输 LADR 扩散LLM加速 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 13 篇,重点解读 5 篇。 方向分布: 扩散模型理论与加速 — 3 篇 文本到图像 / 评测 — 2 篇 图像编辑 — 1 篇 3D 生成与重建 — 4 篇 多模态 / 智能体 — 2 篇 顶会收录: CVPR 2026 x 3 篇 + ICLR 2026 x 1 篇 重点论文深度解读 1. Tri-Prompting: Video Diffusion with Unified Control over Scene, Subject, and Motion 场景/主体/运动统一控制 | Adobe Research | arXiv:2603.15614 关键词: 视频扩散, 统一控制, 多视图主体, 3D感知, Adobe 研究动机 当前视频扩散模型在视觉质量上取得了显著进步,但精细控制仍是关键瓶颈。AI视频创作者需要三种关键控制:场景构图、多视图主体定制、和相机/物体运动调整。现有方法通常孤立处理这些维度,缺乏统一架构支持多维联合控制。 方法原理 提出 Tri-Prompting 统一框架和两阶段训练范式,集成场景构图、多视图主体一致性和运动控制。核心是双条件运动模块:使用 3D 跟踪点控制背景场景,使用下采样 RGB 线索控制前景主体。进一步提出推理时 ControlNet 尺度调度策略,平衡可控性与视觉真实感。支持 3D 感知主体插入任意场景、操纵图像中已有主体等全新工作流。 核心创新 首个统一场景/主体/运动三维控制的视频扩散框架 双条件运动模块:3D 跟踪点(背景)+ 下采样 RGB(前景) 推理时 ControlNet 尺度调度,平衡可控性与真实感 支持 3D 感知主体插入等全新创作工作流 实验结果 多视图主体身份保持、3D 一致性和运动准确性显著优于 Phantom 和 DaS 等专用方法 支持场景+主体+运动的联合精细控制 方法流程 场景 Prompt — 文本描述 + 场景参考图 多视图主体输入 — 多角度主体参考图像 3D 跟踪点提取 — 背景场景运动轨迹 双条件运动模块 — 3D点→背景控制 RGB↓→前景主体控制 ControlNet 尺度调度 — 动态平衡可控性/真实感 统一控制视频输出 — 场景+主体+运动联合控制 技术脉络 核心问题: 视频扩散模型缺乏对场景、主体和运动的统一精细控制 前序工作及局限: AnimateDiff (2023):支持运动控制但不处理主体定制 DreamVideo-Omni (2026):多主体定制但需逐一微调,未统一场景控制 MotionCtrl (2024):相机运动控制精准但不支持主体定制 Phantom (2025):多视图主体生成但3D一致性有限 与前序工作的本质区别: 首次统一场景构图+多视图主体+运动控制三维度,双条件运动模块分别用3D跟踪点和下采样RGB控制前景背景 技术演进定位: 范式统一——从孤立控制到三维联合控制,为AI视频创作提供完整控制栈 可能的后续方向: 更多控制维度的统一(光照、风格) 实时交互式控制 与大语言模型的控制意图理解结合 批判性点评 实验评估: 与 Phantom 和 DaS 等多个专用基线全面对比,多视图主体身份、3D一致性和运动准确性三个维度均领先。消融实验验证了双条件模块和尺度调度的必要性。 新颖性: 三维统一控制是视频生成的重要里程碑,但Adobe闭源可能限制学术影响。创新性:★★★★★ 可复现性: 代码未开源,项目页面已上线。Adobe内部实现可能难以完全复现。 影响力: 影响力 5/5 -- 定义了视频精细控制的完整框架,产业价值极高。 2. Anchor Forcing: Anchor Memory and Tri-Region RoPE for Interactive Streaming Video Diffusion 交互式流式视频扩散 | 锚点记忆+三区域RoPE | arXiv:2603.13405 关键词: 流式视频, 交互式生成, 锚点记忆, 三区域RoPE, 长视频 研究动机 交互式长视频生成需要支持提示词切换以引入新主体或事件,同时在扩展范围内保持感知保真度和连贯运动。现有蒸馏流式视频扩散模型通过滚动 KV 缓存实现长程生成,但存在两个核心失败模式:提示词切换时缓存维护无法同时保留语义上下文和近期潜在线索;蒸馏过程中无界时间索引导致位置分布偏移。 方法原理 提出 Anchor Forcing 缓存中心框架。第一,锚点引导重缓存机制:在锚点缓存中存储 KV 状态,每次提示词切换时从锚点热启动重缓存,减少切换后的证据损失并稳定感知质量。第二,三区域 RoPE:设计区域特定的参考原点,配合 RoPE 重对齐蒸馏,将无界流式索引与预训练 RoPE 体制协调,更好地保留运动先验。 核心创新 识别交互式流式生成的两个特有失败模式 锚点引导重缓存:KV 状态锚点存储 + 热启动,提升切换边界质量 三区域 RoPE + 重对齐蒸馏:解决无界索引的位置分布偏移 与 MemRoPE 思路互补,但专注交互式场景 实验结果 长视频交互式设置中,感知质量和运动指标均优于现有流式基线 支持多次提示词切换且质量不退化 方法流程 提示词 P₁ — 初始场景描述 流式去噪 + KV缓存 — 蒸馏的视频扩散模型 滚动 KV 缓存 锚点缓存存储 — 定期存储 KV 状态 到锚点缓存 提示词切换 P₂ — 用户输入新提示词 引入新主体/事件 锚点热启动重缓存 — 从锚点缓存恢复 减少边界质量损失 三区域 RoPE — 区域特定参考原点 保留运动先验 技术脉络 核心问题: 交互式长视频生成中提示词切换导致质量退化和运动失真 前序工作及局限: MemRoPE (2026-03-17):记忆令牌解决长程上下文,但非交互式设计 StreamDiffusion (2024):实时帧流式,但不支持提示词切换 Attention Sink (2024):静态锚点,提示词切换时信息丢失 DistillVideo (2025):蒸馏流式模型,但RoPE位置漂移未解决 与前序工作的本质区别: 锚点引导重缓存热启动解决切换边界问题,三区域RoPE重对齐解决无界索引的位置分布偏移 技术演进定位: 关键补全——与MemRoPE互补,一个解决长程记忆一个解决交互切换,共同构建流式视频基础设施 可能的后续方向: 与MemRoPE的整合方案 多人协作交互式视频编辑 基于Anchor的视频分支/合并 批判性点评 实验评估: 在长视频交互式设置中全面评估,支持多次提示词切换。与现有流式基线对比感知质量和运动指标均提升。但缺少与MemRoPE的直接对比。 新颖性: 锚点缓存和三区域RoPE是流式视频的基础设施级创新。创新性:★★★★☆ 可复现性: 项目页面已上线,方法描述详细。 影响力: 影响力 4/5 -- 与MemRoPE互补,共同构建流式视频生成基础设施。 3. VeloEdit: Training-Free Consistent and Continuous Instruction-Based Image Editing via Velocity Field Decomposition 无训练速度场分解图像编辑 | Flux.1 Kontext | arXiv:2603.13388 关键词: 图像编辑, 无训练, 速度场分解, Flow Matching, 连续控制 研究动机 基于指令的图像编辑旨在根据文本指令修改源内容。然而,基于 Flow Matching 的现有方法常因去噪重建误差导致非编辑区域漂移,难以保持一致性。此外,它们通常缺乏对编辑强度的细粒度控制。 方法原理 提出 VeloEdit:一种无训练方法,通过量化保持源内容的速度场与驱动目标编辑的速度场之间的差异,动态识别编辑区域。基于此分区,在保留区域用源恢复速度替代编辑速度以强制一致性,在目标区域通过速度插值实现编辑强度的连续调制。直接操作速度场,不依赖复杂注意力操纵或辅助可训练模块。 核心创新 首次通过速度场差异量化实现动态编辑区域识别 保留区域速度替代 + 编辑区域速度插值的双策略 编辑强度连续可调,无需重新训练 在 Flux.1 Kontext 和 Qwen-Image-Edit 上验证 实验结果 在 Flux.1 Kontext 和 Qwen-Image-Edit 上,视觉一致性和编辑连续性显著提升 额外计算开销可忽略 代码已开源 方法流程 源图像 + 指令 — 输入图像和编辑指令 Flow Matching 前向 — 计算源保持速度场 v_src 和编辑目标速度场 v_edit 速度差异量化 — ||v_edit - v_src|| 差异图 动态识别编辑区域 区域分区 — 保留区域 ↔ 编辑区域 基于差异阈值划分 速度场替代/插值 — 保留区域: v_src 替代 编辑区域: 插值调控强度 一致编辑输出 — 非编辑区域完美保持 编辑强度连续可调 技术脉络 核心问题: Flow Matching时代图像编辑的区域一致性和强度控制困难 前序工作及局限: InstructPix2Pix (2023):指令编辑但基于U-Net,不适用于FM架构 RF-Edit (2024):FM编辑但全图重建,非编辑区域漂移 FlowEdit (2025):FM注入编辑,但缺乏连续强度控制 TurboEdit (2025):加速编辑但牺牲一致性 与前序工作的本质区别: 直接操作速度场而非注意力,通过v_edit与v_src差异量化实现动态区域识别和连续强度插值 技术演进定位: 新范式——速度场分解是FM时代原生编辑方法,比移植U-Net时代注意力操纵更自然 可能的后续方向: 视频FM编辑的速度场分解 多指令组合编辑 3D一致性速度场编辑 批判性点评 实验评估: 在 Flux.1 Kontext 和 Qwen-Image-Edit 两个最新模型上验证,视觉一致性和编辑连续性显著提升。但仅在图像编辑测试,未扩展到视频。 新颖性: 速度场分解是FM时代原生的编辑方法论,简洁优雅。创新性:★★★★☆ 可复现性: 代码已开源,直接可复现。 影响力: 影响力 4/5 -- FM编辑的范式性方法,预计会被广泛采用。 4. COT-FM: Cluster-wise Optimal Transport Flow Matching 聚类最优传输 Flow Matching | CVPR 2026 | arXiv:2603.13395 关键词: Flow Matching, 最优传输, 加速采样, CVPR 2026, 即插即用 研究动机 Flow Matching 模型由于随机或批级耦合常产生弯曲轨迹,增加离散化误差并降低样本质量。如何让生成轨迹更直从而减少采样步数,是加速 FM 的核心问题。 方法原理 提出 COT-FM 通用框架,通过聚类目标样本并为每个聚类分配专用源分布(通过反转预训练 FM 模型获得)来重塑概率路径。这种分而治之策略产生更精确的局部传输和显著更直的向量场,且不改变模型架构。作为即插即用方法,可直接应用于任何预训练 FM 模型。 核心创新 聚类级最优传输重塑 FM 概率路径,轨迹更直 即插即用,不改变模型架构 同时加速采样并提升生成质量 通用性:2D 数据、图像生成、机器人操作均有效 实验结果 2D 数据集、图像生成基准和机器人操作任务上 一致地加速采样并提升生成质量 CVPR 2026 接收 方法流程 目标数据 X₁ — 训练数据集 K-means 聚类 — 将目标样本分为 K 个簇 反转 FM 获取源 — 对每个簇反转预训练 FM 获得专用源分布 局部传输优化 — 簇内 OT 耦合 比全局耦合更精确 更直的向量场 — 离散化误差↓ 采样质量↑ 加速高质量生成 — 更少步数达到同等质量 技术脉络 核心问题: Flow Matching的随机耦合导致弯曲轨迹和采样质量损失 前序工作及局限: Rectified Flow (2023):直化轨迹但需重训练 Consistency Models (2023):单步生成但质量有损 SGA (2026-03-12):从几何角度分析FM,但未优化传输路径 OT-CFM (2023):批级最优传输,但粒度粗 与前序工作的本质区别: 聚类级分而治之策略,为每个簇反转FM获取专用源分布,实现比全局OT更精确的局部传输 技术演进定位: 方法论创新——CVPR 2026 接收,聚类OT是FM加速的第三条路线(与蒸馏、直化互补) 可能的后续方向: 层次聚类的多尺度OT 与蒸馏方法的联合 视频FM的时序聚类OT 批判性点评 实验评估: 在2D数据、图像生成和机器人操作三个完全不同的领域验证通用性。CVPR 2026 接收。但图像生成基准的提升幅度需关注。 新颖性: 聚类OT重塑概率路径简洁有力,即插即用特性极好。创新性:★★★★☆ 可复现性: 方法论清晰,可复现性高。 影响力: 影响力 4/5 -- FM加速的新路线,CVPR 2026 认可。 5. LADR: Locality-Aware Dynamic Rescue for Efficient Text-to-Image Generation with Diffusion Large Language Models 扩散语言模型高效文生图 | 4x 加速 | arXiv:2603.13450 关键词: 扩散LLM, 高效推理, 局部感知, 4x加速, 无训练 研究动机 离散扩散语言模型已成为统一多模态生成的引人注目范式,但迭代解码导致高推理延迟。现有加速策略要么需要昂贵重训练,要么未能利用视觉数据固有的 2D 空间冗余性。 方法原理 提出 LADR(局部感知动态拯救),利用图像的空间马尔可夫性质加速推理。优先恢复'生成前沿'处的标记(与已观察像素空间相邻的区域),最大化信息增益。集成形态学邻居识别定位候选标记、有界风险过滤防止错误传播、流形一致逆调度加速掩码密度与扩散轨迹对齐。 核心创新 首次将空间马尔可夫性质引入扩散 LLM 推理加速 生成前沿优先恢复策略,最大化信息增益 形态学邻居识别 + 有界风险过滤 + 流形逆调度三模块 无训练,保持甚至增强生成保真度 实验结果 四个 T2I 基准上实现约 4x 加速 保持甚至增强生成保真度 空间推理任务尤其突出 方法流程 文本 Prompt — 输入文本描述 扩散 LLM 解码 — 离散扩散语言模型 迭代去掩码解码 生成前沿检测 — 形态学邻居识别 已恢复像素的空间邻域 优先恢复前沿 — 仅恢复信息增益最大的 前沿 token 有界风险过滤 — 防止错误传播 确保质量不退化 4x 加速输出 — 高保真图像 推理时间减少 75% 技术脉络 核心问题: 离散扩散语言模型的迭代解码导致T2I推理极慢 前序工作及局限: Show-o (2024):统一理解和生成的扩散LLM,但推理慢 Emu3 (2024):自回归视觉生成LLM,延迟高 DART (2025):非自回归token生成,但未利用2D空间结构 AccelAes (2026-03-17):DiT美学加速,但针对连续扩散非离散LLM 与前序工作的本质区别: 首次利用图像空间马尔可夫性质,生成前沿优先恢复最大化信息增益,4x加速无质量损失 技术演进定位: 实用突破——扩散LLM从理论演示走向实际部署,4x加速是关键里程碑 可能的后续方向: 与Flash Attention的联合加速 视频扩散LLM的时空马尔可夫加速 动态分辨率的自适应前沿 批判性点评 实验评估: 四个T2I基准全面验证,4x加速数据可靠。空间推理任务甚至质量提升是亮点。但仅在T2I上验证,未扩展到T2V。 新颖性: 空间马尔可夫性质的发现和利用是精彩的洞察。创新性:★★★★★ 可复现性: 方法描述清晰,无训练方法易于复现。 影响力: 影响力 5/5 -- 扩散LLM部署的关键里程碑。 批判性点评精选 1. 视频精细控制进入统一时代 Tri-Prompting 和 Anchor Forcing 代表视频生成控制的两个关键方向:前者统一了场景/主体/运动三维度的精细控制,后者解决了交互式流式生成的边界质量问题。结合昨天的 MemRoPE,我们看到一个完整的流式视频控制栈正在形成:MemRoPE 负责长程记忆,Anchor Forcing 负责交互切换,Tri-Prompting 负责精细控制。 2. Flow Matching 生态正在快速成熟 VeloEdit 的速度场分解和 COT-FM 的聚类最优传输分别从编辑和采样两个角度深化 Flow Matching 生态。VeloEdit 表明 FM 的速度场可以直接操作来实现编辑(比移植注意力操纵更自然),COT-FM 则为 FM 加速开辟了蒸馏和直化之外的第三条路线。FM 正从'替代扩散'走向'建立自己的方法论体系'。 3. 扩散 LLM 的部署瓶颈正在被突破 LADR 的 4x 无训练加速表明离散扩散 LLM 的推理效率问题正被认真对待。空间马尔可夫性质是一个精彩的发现——图像 token 的空间局部性可以被利用来避免冗余恢复。这与 DiT 连续扩散的加速(JiT、AccelAes)形成互补,两条技术路线共同推动视觉生成模型的实际部署。 其余论文 · 贡献与效果总结 # 论文 关键词 主要贡献 效果 1 LibraGen (Playing a Balance Game in Subject-Driven Video Generation) 主体驱动 . S2V . DPO . 平衡博弈 将S2V视为平衡博弈,Consis-DPO + Real-Fake DPO + 时间依赖动态CFG 仅千量级数据超越开源和商业S2V模型 2 NumColor (Precise Numeric Color Control in Text-to-Image Generation) 精确颜色 . 数字控制 . Lab空间 . 零样本 Color Token Aggregator + 6707个可学习ColorBook嵌入,CIE Lab空间映射 数字颜色准确度提升4-9x,零样本迁移5个模型 3 EVD (Event-Driven Video Generation) 事件驱动 . 交互幻觉 . 门控采样 . DiT 事件头预测token级活动,事件门控采样减少交互幻觉 状态持久/空间准确/支撑关系/接触稳定全面改善 4 FlashMotion (Few-Step Controllable Video Generation with Trajectory Guidance (CVPR 2026)) 轨迹引导 . 少步生成 . CVPR 2026 . 蒸馏 轨迹适配器+联合蒸馏实现少步可控视频生成 CVPR 2026,代码已开源 5 GlyphPrinter (Region-Grouped DPO for Glyph-Accurate Visual Text Rendering (CVPR 2026)) 文本渲染 . DPO . 字形准确 . CVPR 2026 区域分组DPO文本渲染,无需显式奖励模型 CVPR 2026,字形准确渲染SOTA 6 Spectrum Matching (A Unified Perspective for Superior Diffusability in Latent Diffusion) VAE . 扩散性 . 频谱匹配 . 潜在扩散 频谱匹配假说统一理解VAE在潜在扩散中的可学习性 两个实用方法显著提升VAE扩散性 7 SERUM (Simple Efficient Robust Unifying Marking for Diffusion Image Gen (ICLR 2026)) 水印 . 扩散标记 . ICLR 2026 . 鲁棒 初始噪声中添加水印噪声,训练轻量检测器 ICLR 2026,1% FPR下最高TPR,支持多用户 8 DC-Diffusion (High-Fidelity T2I from VLM via Distribution-Conditioned Diffusion Decoding) VLM . 扩散解码 . 分布条件 . 高保真 Logit-to-Code分布映射将VLM token logits转连续条件信号 仅ImageNet-1K短训练即提升VLM视觉保真度 趋势观察 视频生成精细控制 — Tri-Prompting/Anchor Forcing/LibraGen 分别从场景-主体-运动联合控制/交互式流式/主体定制三个维度推进 Flow Matching 理论深化 — COT-FM 和 Spectrum Matching 分别从传输路径优化和 VAE 扩散性角度深化 FM 基础 扩散 LLM 走向实用 — LADR 4x 加速表明离散扩散 LLM 的推理效率瓶颈正在被攻克 无训练编辑方法涌现 — VeloEdit 速度场分解代表 Flow Matching 时代编辑方法的新范式 生成内容安全与可控 — SERUM 水印 + NumColor 精确颜色 + EVD 事件驱动,多维度提升生成可控性 人工智能炼丹师 整理 | 2026-03-18