搜索到
2
篇与
DiT
的结果
-
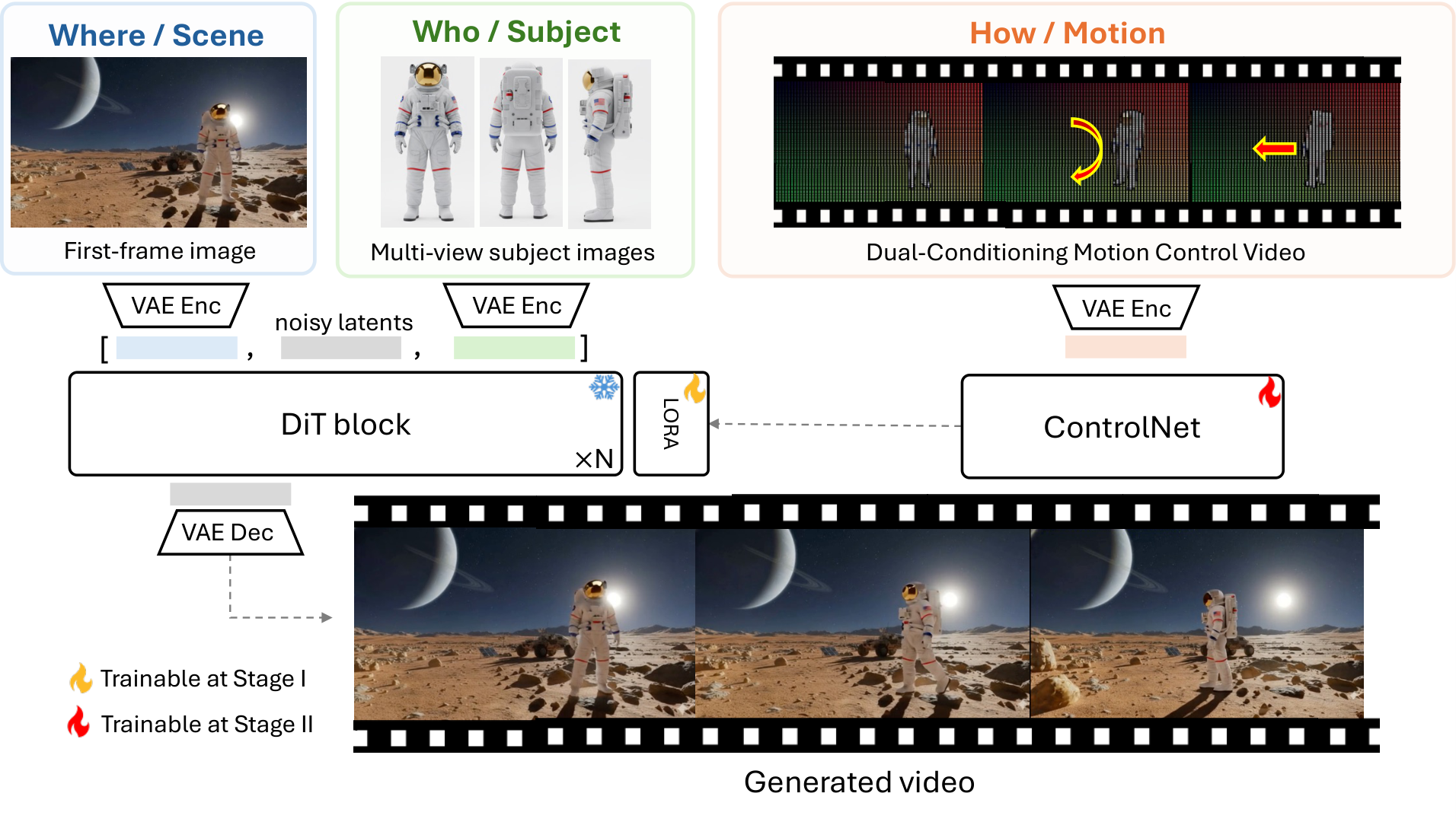
 AIGC 每日速读|2026-03-18|Tri-Prompting|Anchor Forcing|VeloEdit|COT-FM|LADR| [ { "@context": "https://schema.org", "@type": "TechArticle", "headline": "AIGC生成 每日热点论文速读@20260318", "description": "AIGC领域8篇最新论文速读,重点解读LibraGen** (Playing a Balance Game in Subject-Driven Video Generation)、NumColor** (Precise Numeric Color Control in Text-to-Image Generati...", "url": "https://jefxiong.cn/index.php/archives/aigc-daily-papers-20260318.html", "image": "https://jefxiong-1304293246.cos.ap-shenzhen-fsi.myqcloud.com/blog_cover/WechatIMG72.jpeg", "datePublished": "2026-03-18T09:00:00+08:00", "dateModified": "2026-03-18T09:00:00+08:00", "author": { "@type": "Person", "name": "人工智能炼丹师", "url": "https://jefxiong.cn/index.php/about-me.html" }, "publisher": { "@type": "Organization", "name": "人工智能炼丹师", "url": "https://jefxiong.cn", "logo": { "@type": "ImageObject", "url": "https://jefxiong-1304293246.cos.ap-shenzhen-fsi.myqcloud.com/blog_cover/WechatIMG72.jpeg" } }, "mainEntityOfPage": { "@type": "WebPage", "@id": "https://jefxiong.cn/index.php/archives/aigc-daily-papers-20260318.html" }, "keywords": [ "dit", "llm", "diffusion", "图像编辑", "视频生成", "蒸馏", "图像生成", "ai", "扩散模型", "generation" ], "articleSection": "AIGC", "inLanguage": "zh-CN", "citation": [ { "@type": "ScholarlyArticle", "name": "LibraGen** (Playing a Balance Game in Subject-Driven Video Generation)" }, { "@type": "ScholarlyArticle", "name": "NumColor** (Precise Numeric Color Control in Text-to-Image Generation)" }, { "@type": "ScholarlyArticle", "name": "EVD** (Event-Driven Video Generation)" }, { "@type": "ScholarlyArticle", "name": "FlashMotion** (Few-Step Controllable Video Generation with Trajectory Guidance (CVPR 2026))" }, { "@type": "ScholarlyArticle", "name": "GlyphPrinter** (Region-Grouped DPO for Glyph-Accurate Visual Text Rendering (CVPR 2026))" }, { "@type": "ScholarlyArticle", "name": "Spectrum Matching** (A Unified Perspective for Superior Diffusability in Latent Diffusion)" }, { "@type": "ScholarlyArticle", "name": "SERUM** (Simple Efficient Robust Unifying Marking for Diffusion Image Gen (ICLR 2026))" }, { "@type": "ScholarlyArticle", "name": "DC-Diffusion** (High-Fidelity T2I from VLM via Distribution-Conditioned Diffusion Decoding)" } ] }, { "@context": "https://schema.org", "@type": "BreadcrumbList", "itemListElement": [ { "@type": "ListItem", "position": 1, "name": "首页", "item": "https://jefxiong.cn" }, { "@type": "ListItem", "position": 2, "name": "AIGC", "item": "https://jefxiong.cn/index.php/category/AIGC/" }, { "@type": "ListItem", "position": 3, "name": "AIGC生成 每日热点论文速读@20260318", "item": "https://jefxiong.cn/index.php/archives/aigc-daily-papers-20260318.html" } ] } ] AIGC 视觉生成领域 · 每日论文解读 (2026-03-18) 人工智能炼丹师 整理 | 共 13 篇论文 | 重点深度解读 5 篇 今日核心看点 Tri-Prompting 统一控制 Anchor Forcing 流式视频 VeloEdit 速度场编辑 COT-FM 最优传输 LADR 扩散LLM加速 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 13 篇,重点解读 5 篇。 方向分布: 扩散模型理论与加速 — 3 篇 文本到图像 / 评测 — 2 篇 图像编辑 — 1 篇 3D 生成与重建 — 4 篇 多模态 / 智能体 — 2 篇 顶会收录: CVPR 2026 x 3 篇 + ICLR 2026 x 1 篇 重点论文深度解读 1. Tri-Prompting: Video Diffusion with Unified Control over Scene, Subject, and Motion 场景/主体/运动统一控制 | Adobe Research | arXiv:2603.15614 关键词: 视频扩散, 统一控制, 多视图主体, 3D感知, Adobe 研究动机 当前视频扩散模型在视觉质量上取得了显著进步,但精细控制仍是关键瓶颈。AI视频创作者需要三种关键控制:场景构图、多视图主体定制、和相机/物体运动调整。现有方法通常孤立处理这些维度,缺乏统一架构支持多维联合控制。 方法原理 提出 Tri-Prompting 统一框架和两阶段训练范式,集成场景构图、多视图主体一致性和运动控制。核心是双条件运动模块:使用 3D 跟踪点控制背景场景,使用下采样 RGB 线索控制前景主体。进一步提出推理时 ControlNet 尺度调度策略,平衡可控性与视觉真实感。支持 3D 感知主体插入任意场景、操纵图像中已有主体等全新工作流。 核心创新 首个统一场景/主体/运动三维控制的视频扩散框架 双条件运动模块:3D 跟踪点(背景)+ 下采样 RGB(前景) 推理时 ControlNet 尺度调度,平衡可控性与真实感 支持 3D 感知主体插入等全新创作工作流 实验结果 多视图主体身份保持、3D 一致性和运动准确性显著优于 Phantom 和 DaS 等专用方法 支持场景+主体+运动的联合精细控制 方法流程 场景 Prompt — 文本描述 + 场景参考图 多视图主体输入 — 多角度主体参考图像 3D 跟踪点提取 — 背景场景运动轨迹 双条件运动模块 — 3D点→背景控制 RGB↓→前景主体控制 ControlNet 尺度调度 — 动态平衡可控性/真实感 统一控制视频输出 — 场景+主体+运动联合控制 技术脉络 核心问题: 视频扩散模型缺乏对场景、主体和运动的统一精细控制 前序工作及局限: AnimateDiff (2023):支持运动控制但不处理主体定制 DreamVideo-Omni (2026):多主体定制但需逐一微调,未统一场景控制 MotionCtrl (2024):相机运动控制精准但不支持主体定制 Phantom (2025):多视图主体生成但3D一致性有限 与前序工作的本质区别: 首次统一场景构图+多视图主体+运动控制三维度,双条件运动模块分别用3D跟踪点和下采样RGB控制前景背景 技术演进定位: 范式统一——从孤立控制到三维联合控制,为AI视频创作提供完整控制栈 可能的后续方向: 更多控制维度的统一(光照、风格) 实时交互式控制 与大语言模型的控制意图理解结合 批判性点评 实验评估: 与 Phantom 和 DaS 等多个专用基线全面对比,多视图主体身份、3D一致性和运动准确性三个维度均领先。消融实验验证了双条件模块和尺度调度的必要性。 新颖性: 三维统一控制是视频生成的重要里程碑,但Adobe闭源可能限制学术影响。创新性:★★★★★ 可复现性: 代码未开源,项目页面已上线。Adobe内部实现可能难以完全复现。 影响力: 影响力 5/5 -- 定义了视频精细控制的完整框架,产业价值极高。 2. Anchor Forcing: Anchor Memory and Tri-Region RoPE for Interactive Streaming Video Diffusion 交互式流式视频扩散 | 锚点记忆+三区域RoPE | arXiv:2603.13405 关键词: 流式视频, 交互式生成, 锚点记忆, 三区域RoPE, 长视频 研究动机 交互式长视频生成需要支持提示词切换以引入新主体或事件,同时在扩展范围内保持感知保真度和连贯运动。现有蒸馏流式视频扩散模型通过滚动 KV 缓存实现长程生成,但存在两个核心失败模式:提示词切换时缓存维护无法同时保留语义上下文和近期潜在线索;蒸馏过程中无界时间索引导致位置分布偏移。 方法原理 提出 Anchor Forcing 缓存中心框架。第一,锚点引导重缓存机制:在锚点缓存中存储 KV 状态,每次提示词切换时从锚点热启动重缓存,减少切换后的证据损失并稳定感知质量。第二,三区域 RoPE:设计区域特定的参考原点,配合 RoPE 重对齐蒸馏,将无界流式索引与预训练 RoPE 体制协调,更好地保留运动先验。 核心创新 识别交互式流式生成的两个特有失败模式 锚点引导重缓存:KV 状态锚点存储 + 热启动,提升切换边界质量 三区域 RoPE + 重对齐蒸馏:解决无界索引的位置分布偏移 与 MemRoPE 思路互补,但专注交互式场景 实验结果 长视频交互式设置中,感知质量和运动指标均优于现有流式基线 支持多次提示词切换且质量不退化 方法流程 提示词 P₁ — 初始场景描述 流式去噪 + KV缓存 — 蒸馏的视频扩散模型 滚动 KV 缓存 锚点缓存存储 — 定期存储 KV 状态 到锚点缓存 提示词切换 P₂ — 用户输入新提示词 引入新主体/事件 锚点热启动重缓存 — 从锚点缓存恢复 减少边界质量损失 三区域 RoPE — 区域特定参考原点 保留运动先验 技术脉络 核心问题: 交互式长视频生成中提示词切换导致质量退化和运动失真 前序工作及局限: MemRoPE (2026-03-17):记忆令牌解决长程上下文,但非交互式设计 StreamDiffusion (2024):实时帧流式,但不支持提示词切换 Attention Sink (2024):静态锚点,提示词切换时信息丢失 DistillVideo (2025):蒸馏流式模型,但RoPE位置漂移未解决 与前序工作的本质区别: 锚点引导重缓存热启动解决切换边界问题,三区域RoPE重对齐解决无界索引的位置分布偏移 技术演进定位: 关键补全——与MemRoPE互补,一个解决长程记忆一个解决交互切换,共同构建流式视频基础设施 可能的后续方向: 与MemRoPE的整合方案 多人协作交互式视频编辑 基于Anchor的视频分支/合并 批判性点评 实验评估: 在长视频交互式设置中全面评估,支持多次提示词切换。与现有流式基线对比感知质量和运动指标均提升。但缺少与MemRoPE的直接对比。 新颖性: 锚点缓存和三区域RoPE是流式视频的基础设施级创新。创新性:★★★★☆ 可复现性: 项目页面已上线,方法描述详细。 影响力: 影响力 4/5 -- 与MemRoPE互补,共同构建流式视频生成基础设施。 3. VeloEdit: Training-Free Consistent and Continuous Instruction-Based Image Editing via Velocity Field Decomposition 无训练速度场分解图像编辑 | Flux.1 Kontext | arXiv:2603.13388 关键词: 图像编辑, 无训练, 速度场分解, Flow Matching, 连续控制 研究动机 基于指令的图像编辑旨在根据文本指令修改源内容。然而,基于 Flow Matching 的现有方法常因去噪重建误差导致非编辑区域漂移,难以保持一致性。此外,它们通常缺乏对编辑强度的细粒度控制。 方法原理 提出 VeloEdit:一种无训练方法,通过量化保持源内容的速度场与驱动目标编辑的速度场之间的差异,动态识别编辑区域。基于此分区,在保留区域用源恢复速度替代编辑速度以强制一致性,在目标区域通过速度插值实现编辑强度的连续调制。直接操作速度场,不依赖复杂注意力操纵或辅助可训练模块。 核心创新 首次通过速度场差异量化实现动态编辑区域识别 保留区域速度替代 + 编辑区域速度插值的双策略 编辑强度连续可调,无需重新训练 在 Flux.1 Kontext 和 Qwen-Image-Edit 上验证 实验结果 在 Flux.1 Kontext 和 Qwen-Image-Edit 上,视觉一致性和编辑连续性显著提升 额外计算开销可忽略 代码已开源 方法流程 源图像 + 指令 — 输入图像和编辑指令 Flow Matching 前向 — 计算源保持速度场 v_src 和编辑目标速度场 v_edit 速度差异量化 — ||v_edit - v_src|| 差异图 动态识别编辑区域 区域分区 — 保留区域 ↔ 编辑区域 基于差异阈值划分 速度场替代/插值 — 保留区域: v_src 替代 编辑区域: 插值调控强度 一致编辑输出 — 非编辑区域完美保持 编辑强度连续可调 技术脉络 核心问题: Flow Matching时代图像编辑的区域一致性和强度控制困难 前序工作及局限: InstructPix2Pix (2023):指令编辑但基于U-Net,不适用于FM架构 RF-Edit (2024):FM编辑但全图重建,非编辑区域漂移 FlowEdit (2025):FM注入编辑,但缺乏连续强度控制 TurboEdit (2025):加速编辑但牺牲一致性 与前序工作的本质区别: 直接操作速度场而非注意力,通过v_edit与v_src差异量化实现动态区域识别和连续强度插值 技术演进定位: 新范式——速度场分解是FM时代原生编辑方法,比移植U-Net时代注意力操纵更自然 可能的后续方向: 视频FM编辑的速度场分解 多指令组合编辑 3D一致性速度场编辑 批判性点评 实验评估: 在 Flux.1 Kontext 和 Qwen-Image-Edit 两个最新模型上验证,视觉一致性和编辑连续性显著提升。但仅在图像编辑测试,未扩展到视频。 新颖性: 速度场分解是FM时代原生的编辑方法论,简洁优雅。创新性:★★★★☆ 可复现性: 代码已开源,直接可复现。 影响力: 影响力 4/5 -- FM编辑的范式性方法,预计会被广泛采用。 4. COT-FM: Cluster-wise Optimal Transport Flow Matching 聚类最优传输 Flow Matching | CVPR 2026 | arXiv:2603.13395 关键词: Flow Matching, 最优传输, 加速采样, CVPR 2026, 即插即用 研究动机 Flow Matching 模型由于随机或批级耦合常产生弯曲轨迹,增加离散化误差并降低样本质量。如何让生成轨迹更直从而减少采样步数,是加速 FM 的核心问题。 方法原理 提出 COT-FM 通用框架,通过聚类目标样本并为每个聚类分配专用源分布(通过反转预训练 FM 模型获得)来重塑概率路径。这种分而治之策略产生更精确的局部传输和显著更直的向量场,且不改变模型架构。作为即插即用方法,可直接应用于任何预训练 FM 模型。 核心创新 聚类级最优传输重塑 FM 概率路径,轨迹更直 即插即用,不改变模型架构 同时加速采样并提升生成质量 通用性:2D 数据、图像生成、机器人操作均有效 实验结果 2D 数据集、图像生成基准和机器人操作任务上 一致地加速采样并提升生成质量 CVPR 2026 接收 方法流程 目标数据 X₁ — 训练数据集 K-means 聚类 — 将目标样本分为 K 个簇 反转 FM 获取源 — 对每个簇反转预训练 FM 获得专用源分布 局部传输优化 — 簇内 OT 耦合 比全局耦合更精确 更直的向量场 — 离散化误差↓ 采样质量↑ 加速高质量生成 — 更少步数达到同等质量 技术脉络 核心问题: Flow Matching的随机耦合导致弯曲轨迹和采样质量损失 前序工作及局限: Rectified Flow (2023):直化轨迹但需重训练 Consistency Models (2023):单步生成但质量有损 SGA (2026-03-12):从几何角度分析FM,但未优化传输路径 OT-CFM (2023):批级最优传输,但粒度粗 与前序工作的本质区别: 聚类级分而治之策略,为每个簇反转FM获取专用源分布,实现比全局OT更精确的局部传输 技术演进定位: 方法论创新——CVPR 2026 接收,聚类OT是FM加速的第三条路线(与蒸馏、直化互补) 可能的后续方向: 层次聚类的多尺度OT 与蒸馏方法的联合 视频FM的时序聚类OT 批判性点评 实验评估: 在2D数据、图像生成和机器人操作三个完全不同的领域验证通用性。CVPR 2026 接收。但图像生成基准的提升幅度需关注。 新颖性: 聚类OT重塑概率路径简洁有力,即插即用特性极好。创新性:★★★★☆ 可复现性: 方法论清晰,可复现性高。 影响力: 影响力 4/5 -- FM加速的新路线,CVPR 2026 认可。 5. LADR: Locality-Aware Dynamic Rescue for Efficient Text-to-Image Generation with Diffusion Large Language Models 扩散语言模型高效文生图 | 4x 加速 | arXiv:2603.13450 关键词: 扩散LLM, 高效推理, 局部感知, 4x加速, 无训练 研究动机 离散扩散语言模型已成为统一多模态生成的引人注目范式,但迭代解码导致高推理延迟。现有加速策略要么需要昂贵重训练,要么未能利用视觉数据固有的 2D 空间冗余性。 方法原理 提出 LADR(局部感知动态拯救),利用图像的空间马尔可夫性质加速推理。优先恢复'生成前沿'处的标记(与已观察像素空间相邻的区域),最大化信息增益。集成形态学邻居识别定位候选标记、有界风险过滤防止错误传播、流形一致逆调度加速掩码密度与扩散轨迹对齐。 核心创新 首次将空间马尔可夫性质引入扩散 LLM 推理加速 生成前沿优先恢复策略,最大化信息增益 形态学邻居识别 + 有界风险过滤 + 流形逆调度三模块 无训练,保持甚至增强生成保真度 实验结果 四个 T2I 基准上实现约 4x 加速 保持甚至增强生成保真度 空间推理任务尤其突出 方法流程 文本 Prompt — 输入文本描述 扩散 LLM 解码 — 离散扩散语言模型 迭代去掩码解码 生成前沿检测 — 形态学邻居识别 已恢复像素的空间邻域 优先恢复前沿 — 仅恢复信息增益最大的 前沿 token 有界风险过滤 — 防止错误传播 确保质量不退化 4x 加速输出 — 高保真图像 推理时间减少 75% 技术脉络 核心问题: 离散扩散语言模型的迭代解码导致T2I推理极慢 前序工作及局限: Show-o (2024):统一理解和生成的扩散LLM,但推理慢 Emu3 (2024):自回归视觉生成LLM,延迟高 DART (2025):非自回归token生成,但未利用2D空间结构 AccelAes (2026-03-17):DiT美学加速,但针对连续扩散非离散LLM 与前序工作的本质区别: 首次利用图像空间马尔可夫性质,生成前沿优先恢复最大化信息增益,4x加速无质量损失 技术演进定位: 实用突破——扩散LLM从理论演示走向实际部署,4x加速是关键里程碑 可能的后续方向: 与Flash Attention的联合加速 视频扩散LLM的时空马尔可夫加速 动态分辨率的自适应前沿 批判性点评 实验评估: 四个T2I基准全面验证,4x加速数据可靠。空间推理任务甚至质量提升是亮点。但仅在T2I上验证,未扩展到T2V。 新颖性: 空间马尔可夫性质的发现和利用是精彩的洞察。创新性:★★★★★ 可复现性: 方法描述清晰,无训练方法易于复现。 影响力: 影响力 5/5 -- 扩散LLM部署的关键里程碑。 批判性点评精选 1. 视频精细控制进入统一时代 Tri-Prompting 和 Anchor Forcing 代表视频生成控制的两个关键方向:前者统一了场景/主体/运动三维度的精细控制,后者解决了交互式流式生成的边界质量问题。结合昨天的 MemRoPE,我们看到一个完整的流式视频控制栈正在形成:MemRoPE 负责长程记忆,Anchor Forcing 负责交互切换,Tri-Prompting 负责精细控制。 2. Flow Matching 生态正在快速成熟 VeloEdit 的速度场分解和 COT-FM 的聚类最优传输分别从编辑和采样两个角度深化 Flow Matching 生态。VeloEdit 表明 FM 的速度场可以直接操作来实现编辑(比移植注意力操纵更自然),COT-FM 则为 FM 加速开辟了蒸馏和直化之外的第三条路线。FM 正从'替代扩散'走向'建立自己的方法论体系'。 3. 扩散 LLM 的部署瓶颈正在被突破 LADR 的 4x 无训练加速表明离散扩散 LLM 的推理效率问题正被认真对待。空间马尔可夫性质是一个精彩的发现——图像 token 的空间局部性可以被利用来避免冗余恢复。这与 DiT 连续扩散的加速(JiT、AccelAes)形成互补,两条技术路线共同推动视觉生成模型的实际部署。 其余论文 · 贡献与效果总结 # 论文 关键词 主要贡献 效果 1 LibraGen (Playing a Balance Game in Subject-Driven Video Generation) 主体驱动 . S2V . DPO . 平衡博弈 将S2V视为平衡博弈,Consis-DPO + Real-Fake DPO + 时间依赖动态CFG 仅千量级数据超越开源和商业S2V模型 2 NumColor (Precise Numeric Color Control in Text-to-Image Generation) 精确颜色 . 数字控制 . Lab空间 . 零样本 Color Token Aggregator + 6707个可学习ColorBook嵌入,CIE Lab空间映射 数字颜色准确度提升4-9x,零样本迁移5个模型 3 EVD (Event-Driven Video Generation) 事件驱动 . 交互幻觉 . 门控采样 . DiT 事件头预测token级活动,事件门控采样减少交互幻觉 状态持久/空间准确/支撑关系/接触稳定全面改善 4 FlashMotion (Few-Step Controllable Video Generation with Trajectory Guidance (CVPR 2026)) 轨迹引导 . 少步生成 . CVPR 2026 . 蒸馏 轨迹适配器+联合蒸馏实现少步可控视频生成 CVPR 2026,代码已开源 5 GlyphPrinter (Region-Grouped DPO for Glyph-Accurate Visual Text Rendering (CVPR 2026)) 文本渲染 . DPO . 字形准确 . CVPR 2026 区域分组DPO文本渲染,无需显式奖励模型 CVPR 2026,字形准确渲染SOTA 6 Spectrum Matching (A Unified Perspective for Superior Diffusability in Latent Diffusion) VAE . 扩散性 . 频谱匹配 . 潜在扩散 频谱匹配假说统一理解VAE在潜在扩散中的可学习性 两个实用方法显著提升VAE扩散性 7 SERUM (Simple Efficient Robust Unifying Marking for Diffusion Image Gen (ICLR 2026)) 水印 . 扩散标记 . ICLR 2026 . 鲁棒 初始噪声中添加水印噪声,训练轻量检测器 ICLR 2026,1% FPR下最高TPR,支持多用户 8 DC-Diffusion (High-Fidelity T2I from VLM via Distribution-Conditioned Diffusion Decoding) VLM . 扩散解码 . 分布条件 . 高保真 Logit-to-Code分布映射将VLM token logits转连续条件信号 仅ImageNet-1K短训练即提升VLM视觉保真度 趋势观察 视频生成精细控制 — Tri-Prompting/Anchor Forcing/LibraGen 分别从场景-主体-运动联合控制/交互式流式/主体定制三个维度推进 Flow Matching 理论深化 — COT-FM 和 Spectrum Matching 分别从传输路径优化和 VAE 扩散性角度深化 FM 基础 扩散 LLM 走向实用 — LADR 4x 加速表明离散扩散 LLM 的推理效率瓶颈正在被攻克 无训练编辑方法涌现 — VeloEdit 速度场分解代表 Flow Matching 时代编辑方法的新范式 生成内容安全与可控 — SERUM 水印 + NumColor 精确颜色 + EVD 事件驱动,多维度提升生成可控性 人工智能炼丹师 整理 | 2026-03-18
AIGC 每日速读|2026-03-18|Tri-Prompting|Anchor Forcing|VeloEdit|COT-FM|LADR| [ { "@context": "https://schema.org", "@type": "TechArticle", "headline": "AIGC生成 每日热点论文速读@20260318", "description": "AIGC领域8篇最新论文速读,重点解读LibraGen** (Playing a Balance Game in Subject-Driven Video Generation)、NumColor** (Precise Numeric Color Control in Text-to-Image Generati...", "url": "https://jefxiong.cn/index.php/archives/aigc-daily-papers-20260318.html", "image": "https://jefxiong-1304293246.cos.ap-shenzhen-fsi.myqcloud.com/blog_cover/WechatIMG72.jpeg", "datePublished": "2026-03-18T09:00:00+08:00", "dateModified": "2026-03-18T09:00:00+08:00", "author": { "@type": "Person", "name": "人工智能炼丹师", "url": "https://jefxiong.cn/index.php/about-me.html" }, "publisher": { "@type": "Organization", "name": "人工智能炼丹师", "url": "https://jefxiong.cn", "logo": { "@type": "ImageObject", "url": "https://jefxiong-1304293246.cos.ap-shenzhen-fsi.myqcloud.com/blog_cover/WechatIMG72.jpeg" } }, "mainEntityOfPage": { "@type": "WebPage", "@id": "https://jefxiong.cn/index.php/archives/aigc-daily-papers-20260318.html" }, "keywords": [ "dit", "llm", "diffusion", "图像编辑", "视频生成", "蒸馏", "图像生成", "ai", "扩散模型", "generation" ], "articleSection": "AIGC", "inLanguage": "zh-CN", "citation": [ { "@type": "ScholarlyArticle", "name": "LibraGen** (Playing a Balance Game in Subject-Driven Video Generation)" }, { "@type": "ScholarlyArticle", "name": "NumColor** (Precise Numeric Color Control in Text-to-Image Generation)" }, { "@type": "ScholarlyArticle", "name": "EVD** (Event-Driven Video Generation)" }, { "@type": "ScholarlyArticle", "name": "FlashMotion** (Few-Step Controllable Video Generation with Trajectory Guidance (CVPR 2026))" }, { "@type": "ScholarlyArticle", "name": "GlyphPrinter** (Region-Grouped DPO for Glyph-Accurate Visual Text Rendering (CVPR 2026))" }, { "@type": "ScholarlyArticle", "name": "Spectrum Matching** (A Unified Perspective for Superior Diffusability in Latent Diffusion)" }, { "@type": "ScholarlyArticle", "name": "SERUM** (Simple Efficient Robust Unifying Marking for Diffusion Image Gen (ICLR 2026))" }, { "@type": "ScholarlyArticle", "name": "DC-Diffusion** (High-Fidelity T2I from VLM via Distribution-Conditioned Diffusion Decoding)" } ] }, { "@context": "https://schema.org", "@type": "BreadcrumbList", "itemListElement": [ { "@type": "ListItem", "position": 1, "name": "首页", "item": "https://jefxiong.cn" }, { "@type": "ListItem", "position": 2, "name": "AIGC", "item": "https://jefxiong.cn/index.php/category/AIGC/" }, { "@type": "ListItem", "position": 3, "name": "AIGC生成 每日热点论文速读@20260318", "item": "https://jefxiong.cn/index.php/archives/aigc-daily-papers-20260318.html" } ] } ] AIGC 视觉生成领域 · 每日论文解读 (2026-03-18) 人工智能炼丹师 整理 | 共 13 篇论文 | 重点深度解读 5 篇 今日核心看点 Tri-Prompting 统一控制 Anchor Forcing 流式视频 VeloEdit 速度场编辑 COT-FM 最优传输 LADR 扩散LLM加速 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 13 篇,重点解读 5 篇。 方向分布: 扩散模型理论与加速 — 3 篇 文本到图像 / 评测 — 2 篇 图像编辑 — 1 篇 3D 生成与重建 — 4 篇 多模态 / 智能体 — 2 篇 顶会收录: CVPR 2026 x 3 篇 + ICLR 2026 x 1 篇 重点论文深度解读 1. Tri-Prompting: Video Diffusion with Unified Control over Scene, Subject, and Motion 场景/主体/运动统一控制 | Adobe Research | arXiv:2603.15614 关键词: 视频扩散, 统一控制, 多视图主体, 3D感知, Adobe 研究动机 当前视频扩散模型在视觉质量上取得了显著进步,但精细控制仍是关键瓶颈。AI视频创作者需要三种关键控制:场景构图、多视图主体定制、和相机/物体运动调整。现有方法通常孤立处理这些维度,缺乏统一架构支持多维联合控制。 方法原理 提出 Tri-Prompting 统一框架和两阶段训练范式,集成场景构图、多视图主体一致性和运动控制。核心是双条件运动模块:使用 3D 跟踪点控制背景场景,使用下采样 RGB 线索控制前景主体。进一步提出推理时 ControlNet 尺度调度策略,平衡可控性与视觉真实感。支持 3D 感知主体插入任意场景、操纵图像中已有主体等全新工作流。 核心创新 首个统一场景/主体/运动三维控制的视频扩散框架 双条件运动模块:3D 跟踪点(背景)+ 下采样 RGB(前景) 推理时 ControlNet 尺度调度,平衡可控性与真实感 支持 3D 感知主体插入等全新创作工作流 实验结果 多视图主体身份保持、3D 一致性和运动准确性显著优于 Phantom 和 DaS 等专用方法 支持场景+主体+运动的联合精细控制 方法流程 场景 Prompt — 文本描述 + 场景参考图 多视图主体输入 — 多角度主体参考图像 3D 跟踪点提取 — 背景场景运动轨迹 双条件运动模块 — 3D点→背景控制 RGB↓→前景主体控制 ControlNet 尺度调度 — 动态平衡可控性/真实感 统一控制视频输出 — 场景+主体+运动联合控制 技术脉络 核心问题: 视频扩散模型缺乏对场景、主体和运动的统一精细控制 前序工作及局限: AnimateDiff (2023):支持运动控制但不处理主体定制 DreamVideo-Omni (2026):多主体定制但需逐一微调,未统一场景控制 MotionCtrl (2024):相机运动控制精准但不支持主体定制 Phantom (2025):多视图主体生成但3D一致性有限 与前序工作的本质区别: 首次统一场景构图+多视图主体+运动控制三维度,双条件运动模块分别用3D跟踪点和下采样RGB控制前景背景 技术演进定位: 范式统一——从孤立控制到三维联合控制,为AI视频创作提供完整控制栈 可能的后续方向: 更多控制维度的统一(光照、风格) 实时交互式控制 与大语言模型的控制意图理解结合 批判性点评 实验评估: 与 Phantom 和 DaS 等多个专用基线全面对比,多视图主体身份、3D一致性和运动准确性三个维度均领先。消融实验验证了双条件模块和尺度调度的必要性。 新颖性: 三维统一控制是视频生成的重要里程碑,但Adobe闭源可能限制学术影响。创新性:★★★★★ 可复现性: 代码未开源,项目页面已上线。Adobe内部实现可能难以完全复现。 影响力: 影响力 5/5 -- 定义了视频精细控制的完整框架,产业价值极高。 2. Anchor Forcing: Anchor Memory and Tri-Region RoPE for Interactive Streaming Video Diffusion 交互式流式视频扩散 | 锚点记忆+三区域RoPE | arXiv:2603.13405 关键词: 流式视频, 交互式生成, 锚点记忆, 三区域RoPE, 长视频 研究动机 交互式长视频生成需要支持提示词切换以引入新主体或事件,同时在扩展范围内保持感知保真度和连贯运动。现有蒸馏流式视频扩散模型通过滚动 KV 缓存实现长程生成,但存在两个核心失败模式:提示词切换时缓存维护无法同时保留语义上下文和近期潜在线索;蒸馏过程中无界时间索引导致位置分布偏移。 方法原理 提出 Anchor Forcing 缓存中心框架。第一,锚点引导重缓存机制:在锚点缓存中存储 KV 状态,每次提示词切换时从锚点热启动重缓存,减少切换后的证据损失并稳定感知质量。第二,三区域 RoPE:设计区域特定的参考原点,配合 RoPE 重对齐蒸馏,将无界流式索引与预训练 RoPE 体制协调,更好地保留运动先验。 核心创新 识别交互式流式生成的两个特有失败模式 锚点引导重缓存:KV 状态锚点存储 + 热启动,提升切换边界质量 三区域 RoPE + 重对齐蒸馏:解决无界索引的位置分布偏移 与 MemRoPE 思路互补,但专注交互式场景 实验结果 长视频交互式设置中,感知质量和运动指标均优于现有流式基线 支持多次提示词切换且质量不退化 方法流程 提示词 P₁ — 初始场景描述 流式去噪 + KV缓存 — 蒸馏的视频扩散模型 滚动 KV 缓存 锚点缓存存储 — 定期存储 KV 状态 到锚点缓存 提示词切换 P₂ — 用户输入新提示词 引入新主体/事件 锚点热启动重缓存 — 从锚点缓存恢复 减少边界质量损失 三区域 RoPE — 区域特定参考原点 保留运动先验 技术脉络 核心问题: 交互式长视频生成中提示词切换导致质量退化和运动失真 前序工作及局限: MemRoPE (2026-03-17):记忆令牌解决长程上下文,但非交互式设计 StreamDiffusion (2024):实时帧流式,但不支持提示词切换 Attention Sink (2024):静态锚点,提示词切换时信息丢失 DistillVideo (2025):蒸馏流式模型,但RoPE位置漂移未解决 与前序工作的本质区别: 锚点引导重缓存热启动解决切换边界问题,三区域RoPE重对齐解决无界索引的位置分布偏移 技术演进定位: 关键补全——与MemRoPE互补,一个解决长程记忆一个解决交互切换,共同构建流式视频基础设施 可能的后续方向: 与MemRoPE的整合方案 多人协作交互式视频编辑 基于Anchor的视频分支/合并 批判性点评 实验评估: 在长视频交互式设置中全面评估,支持多次提示词切换。与现有流式基线对比感知质量和运动指标均提升。但缺少与MemRoPE的直接对比。 新颖性: 锚点缓存和三区域RoPE是流式视频的基础设施级创新。创新性:★★★★☆ 可复现性: 项目页面已上线,方法描述详细。 影响力: 影响力 4/5 -- 与MemRoPE互补,共同构建流式视频生成基础设施。 3. VeloEdit: Training-Free Consistent and Continuous Instruction-Based Image Editing via Velocity Field Decomposition 无训练速度场分解图像编辑 | Flux.1 Kontext | arXiv:2603.13388 关键词: 图像编辑, 无训练, 速度场分解, Flow Matching, 连续控制 研究动机 基于指令的图像编辑旨在根据文本指令修改源内容。然而,基于 Flow Matching 的现有方法常因去噪重建误差导致非编辑区域漂移,难以保持一致性。此外,它们通常缺乏对编辑强度的细粒度控制。 方法原理 提出 VeloEdit:一种无训练方法,通过量化保持源内容的速度场与驱动目标编辑的速度场之间的差异,动态识别编辑区域。基于此分区,在保留区域用源恢复速度替代编辑速度以强制一致性,在目标区域通过速度插值实现编辑强度的连续调制。直接操作速度场,不依赖复杂注意力操纵或辅助可训练模块。 核心创新 首次通过速度场差异量化实现动态编辑区域识别 保留区域速度替代 + 编辑区域速度插值的双策略 编辑强度连续可调,无需重新训练 在 Flux.1 Kontext 和 Qwen-Image-Edit 上验证 实验结果 在 Flux.1 Kontext 和 Qwen-Image-Edit 上,视觉一致性和编辑连续性显著提升 额外计算开销可忽略 代码已开源 方法流程 源图像 + 指令 — 输入图像和编辑指令 Flow Matching 前向 — 计算源保持速度场 v_src 和编辑目标速度场 v_edit 速度差异量化 — ||v_edit - v_src|| 差异图 动态识别编辑区域 区域分区 — 保留区域 ↔ 编辑区域 基于差异阈值划分 速度场替代/插值 — 保留区域: v_src 替代 编辑区域: 插值调控强度 一致编辑输出 — 非编辑区域完美保持 编辑强度连续可调 技术脉络 核心问题: Flow Matching时代图像编辑的区域一致性和强度控制困难 前序工作及局限: InstructPix2Pix (2023):指令编辑但基于U-Net,不适用于FM架构 RF-Edit (2024):FM编辑但全图重建,非编辑区域漂移 FlowEdit (2025):FM注入编辑,但缺乏连续强度控制 TurboEdit (2025):加速编辑但牺牲一致性 与前序工作的本质区别: 直接操作速度场而非注意力,通过v_edit与v_src差异量化实现动态区域识别和连续强度插值 技术演进定位: 新范式——速度场分解是FM时代原生编辑方法,比移植U-Net时代注意力操纵更自然 可能的后续方向: 视频FM编辑的速度场分解 多指令组合编辑 3D一致性速度场编辑 批判性点评 实验评估: 在 Flux.1 Kontext 和 Qwen-Image-Edit 两个最新模型上验证,视觉一致性和编辑连续性显著提升。但仅在图像编辑测试,未扩展到视频。 新颖性: 速度场分解是FM时代原生的编辑方法论,简洁优雅。创新性:★★★★☆ 可复现性: 代码已开源,直接可复现。 影响力: 影响力 4/5 -- FM编辑的范式性方法,预计会被广泛采用。 4. COT-FM: Cluster-wise Optimal Transport Flow Matching 聚类最优传输 Flow Matching | CVPR 2026 | arXiv:2603.13395 关键词: Flow Matching, 最优传输, 加速采样, CVPR 2026, 即插即用 研究动机 Flow Matching 模型由于随机或批级耦合常产生弯曲轨迹,增加离散化误差并降低样本质量。如何让生成轨迹更直从而减少采样步数,是加速 FM 的核心问题。 方法原理 提出 COT-FM 通用框架,通过聚类目标样本并为每个聚类分配专用源分布(通过反转预训练 FM 模型获得)来重塑概率路径。这种分而治之策略产生更精确的局部传输和显著更直的向量场,且不改变模型架构。作为即插即用方法,可直接应用于任何预训练 FM 模型。 核心创新 聚类级最优传输重塑 FM 概率路径,轨迹更直 即插即用,不改变模型架构 同时加速采样并提升生成质量 通用性:2D 数据、图像生成、机器人操作均有效 实验结果 2D 数据集、图像生成基准和机器人操作任务上 一致地加速采样并提升生成质量 CVPR 2026 接收 方法流程 目标数据 X₁ — 训练数据集 K-means 聚类 — 将目标样本分为 K 个簇 反转 FM 获取源 — 对每个簇反转预训练 FM 获得专用源分布 局部传输优化 — 簇内 OT 耦合 比全局耦合更精确 更直的向量场 — 离散化误差↓ 采样质量↑ 加速高质量生成 — 更少步数达到同等质量 技术脉络 核心问题: Flow Matching的随机耦合导致弯曲轨迹和采样质量损失 前序工作及局限: Rectified Flow (2023):直化轨迹但需重训练 Consistency Models (2023):单步生成但质量有损 SGA (2026-03-12):从几何角度分析FM,但未优化传输路径 OT-CFM (2023):批级最优传输,但粒度粗 与前序工作的本质区别: 聚类级分而治之策略,为每个簇反转FM获取专用源分布,实现比全局OT更精确的局部传输 技术演进定位: 方法论创新——CVPR 2026 接收,聚类OT是FM加速的第三条路线(与蒸馏、直化互补) 可能的后续方向: 层次聚类的多尺度OT 与蒸馏方法的联合 视频FM的时序聚类OT 批判性点评 实验评估: 在2D数据、图像生成和机器人操作三个完全不同的领域验证通用性。CVPR 2026 接收。但图像生成基准的提升幅度需关注。 新颖性: 聚类OT重塑概率路径简洁有力,即插即用特性极好。创新性:★★★★☆ 可复现性: 方法论清晰,可复现性高。 影响力: 影响力 4/5 -- FM加速的新路线,CVPR 2026 认可。 5. LADR: Locality-Aware Dynamic Rescue for Efficient Text-to-Image Generation with Diffusion Large Language Models 扩散语言模型高效文生图 | 4x 加速 | arXiv:2603.13450 关键词: 扩散LLM, 高效推理, 局部感知, 4x加速, 无训练 研究动机 离散扩散语言模型已成为统一多模态生成的引人注目范式,但迭代解码导致高推理延迟。现有加速策略要么需要昂贵重训练,要么未能利用视觉数据固有的 2D 空间冗余性。 方法原理 提出 LADR(局部感知动态拯救),利用图像的空间马尔可夫性质加速推理。优先恢复'生成前沿'处的标记(与已观察像素空间相邻的区域),最大化信息增益。集成形态学邻居识别定位候选标记、有界风险过滤防止错误传播、流形一致逆调度加速掩码密度与扩散轨迹对齐。 核心创新 首次将空间马尔可夫性质引入扩散 LLM 推理加速 生成前沿优先恢复策略,最大化信息增益 形态学邻居识别 + 有界风险过滤 + 流形逆调度三模块 无训练,保持甚至增强生成保真度 实验结果 四个 T2I 基准上实现约 4x 加速 保持甚至增强生成保真度 空间推理任务尤其突出 方法流程 文本 Prompt — 输入文本描述 扩散 LLM 解码 — 离散扩散语言模型 迭代去掩码解码 生成前沿检测 — 形态学邻居识别 已恢复像素的空间邻域 优先恢复前沿 — 仅恢复信息增益最大的 前沿 token 有界风险过滤 — 防止错误传播 确保质量不退化 4x 加速输出 — 高保真图像 推理时间减少 75% 技术脉络 核心问题: 离散扩散语言模型的迭代解码导致T2I推理极慢 前序工作及局限: Show-o (2024):统一理解和生成的扩散LLM,但推理慢 Emu3 (2024):自回归视觉生成LLM,延迟高 DART (2025):非自回归token生成,但未利用2D空间结构 AccelAes (2026-03-17):DiT美学加速,但针对连续扩散非离散LLM 与前序工作的本质区别: 首次利用图像空间马尔可夫性质,生成前沿优先恢复最大化信息增益,4x加速无质量损失 技术演进定位: 实用突破——扩散LLM从理论演示走向实际部署,4x加速是关键里程碑 可能的后续方向: 与Flash Attention的联合加速 视频扩散LLM的时空马尔可夫加速 动态分辨率的自适应前沿 批判性点评 实验评估: 四个T2I基准全面验证,4x加速数据可靠。空间推理任务甚至质量提升是亮点。但仅在T2I上验证,未扩展到T2V。 新颖性: 空间马尔可夫性质的发现和利用是精彩的洞察。创新性:★★★★★ 可复现性: 方法描述清晰,无训练方法易于复现。 影响力: 影响力 5/5 -- 扩散LLM部署的关键里程碑。 批判性点评精选 1. 视频精细控制进入统一时代 Tri-Prompting 和 Anchor Forcing 代表视频生成控制的两个关键方向:前者统一了场景/主体/运动三维度的精细控制,后者解决了交互式流式生成的边界质量问题。结合昨天的 MemRoPE,我们看到一个完整的流式视频控制栈正在形成:MemRoPE 负责长程记忆,Anchor Forcing 负责交互切换,Tri-Prompting 负责精细控制。 2. Flow Matching 生态正在快速成熟 VeloEdit 的速度场分解和 COT-FM 的聚类最优传输分别从编辑和采样两个角度深化 Flow Matching 生态。VeloEdit 表明 FM 的速度场可以直接操作来实现编辑(比移植注意力操纵更自然),COT-FM 则为 FM 加速开辟了蒸馏和直化之外的第三条路线。FM 正从'替代扩散'走向'建立自己的方法论体系'。 3. 扩散 LLM 的部署瓶颈正在被突破 LADR 的 4x 无训练加速表明离散扩散 LLM 的推理效率问题正被认真对待。空间马尔可夫性质是一个精彩的发现——图像 token 的空间局部性可以被利用来避免冗余恢复。这与 DiT 连续扩散的加速(JiT、AccelAes)形成互补,两条技术路线共同推动视觉生成模型的实际部署。 其余论文 · 贡献与效果总结 # 论文 关键词 主要贡献 效果 1 LibraGen (Playing a Balance Game in Subject-Driven Video Generation) 主体驱动 . S2V . DPO . 平衡博弈 将S2V视为平衡博弈,Consis-DPO + Real-Fake DPO + 时间依赖动态CFG 仅千量级数据超越开源和商业S2V模型 2 NumColor (Precise Numeric Color Control in Text-to-Image Generation) 精确颜色 . 数字控制 . Lab空间 . 零样本 Color Token Aggregator + 6707个可学习ColorBook嵌入,CIE Lab空间映射 数字颜色准确度提升4-9x,零样本迁移5个模型 3 EVD (Event-Driven Video Generation) 事件驱动 . 交互幻觉 . 门控采样 . DiT 事件头预测token级活动,事件门控采样减少交互幻觉 状态持久/空间准确/支撑关系/接触稳定全面改善 4 FlashMotion (Few-Step Controllable Video Generation with Trajectory Guidance (CVPR 2026)) 轨迹引导 . 少步生成 . CVPR 2026 . 蒸馏 轨迹适配器+联合蒸馏实现少步可控视频生成 CVPR 2026,代码已开源 5 GlyphPrinter (Region-Grouped DPO for Glyph-Accurate Visual Text Rendering (CVPR 2026)) 文本渲染 . DPO . 字形准确 . CVPR 2026 区域分组DPO文本渲染,无需显式奖励模型 CVPR 2026,字形准确渲染SOTA 6 Spectrum Matching (A Unified Perspective for Superior Diffusability in Latent Diffusion) VAE . 扩散性 . 频谱匹配 . 潜在扩散 频谱匹配假说统一理解VAE在潜在扩散中的可学习性 两个实用方法显著提升VAE扩散性 7 SERUM (Simple Efficient Robust Unifying Marking for Diffusion Image Gen (ICLR 2026)) 水印 . 扩散标记 . ICLR 2026 . 鲁棒 初始噪声中添加水印噪声,训练轻量检测器 ICLR 2026,1% FPR下最高TPR,支持多用户 8 DC-Diffusion (High-Fidelity T2I from VLM via Distribution-Conditioned Diffusion Decoding) VLM . 扩散解码 . 分布条件 . 高保真 Logit-to-Code分布映射将VLM token logits转连续条件信号 仅ImageNet-1K短训练即提升VLM视觉保真度 趋势观察 视频生成精细控制 — Tri-Prompting/Anchor Forcing/LibraGen 分别从场景-主体-运动联合控制/交互式流式/主体定制三个维度推进 Flow Matching 理论深化 — COT-FM 和 Spectrum Matching 分别从传输路径优化和 VAE 扩散性角度深化 FM 基础 扩散 LLM 走向实用 — LADR 4x 加速表明离散扩散 LLM 的推理效率瓶颈正在被攻克 无训练编辑方法涌现 — VeloEdit 速度场分解代表 Flow Matching 时代编辑方法的新范式 生成内容安全与可控 — SERUM 水印 + NumColor 精确颜色 + EVD 事件驱动,多维度提升生成可控性 人工智能炼丹师 整理 | 2026-03-18 -
AIGC 周末专题深度解读:视频扩散 Transformer 高效推理 AIGC 周末专题深度解读:视频扩散 Transformer 高效推理 专题方向:视频 DiT 中的稀疏注意力、线性注意力与推理加速 覆盖时间:2026年3月2日 — 2026年3月13日 整理:人工智能炼丹师 日期:2026年3月14日(周六) 一、专题概览 本周是视频扩散 Transformer(Video DiT)高效推理方向的"论文爆发周"。短短一周内,arXiv 上出现了 9 篇 高度聚焦于视频 DiT 注意力加速与推理优化的论文,覆盖了从稀疏注意力、线性注意力、结构化注意力,到蒸馏压缩、缓存+剪枝、系统级并行优化的完整技术栈。 核心背景 当前主流视频生成模型(Wan 2.1/2.2、HunyuanVideo、Mochi 等)均采用 Diffusion Transformer(DiT)架构,其核心瓶颈在于 全注意力(Full 3D Attention)的 O(N²) 复杂度。一段 5 秒 720P 视频的 token 序列长度可达数十万,全注意力的计算量和显存占用极其惊人。因此,如何在保持生成质量的前提下大幅降低注意力计算成本,成为本周研究的核心主题。 本周论文全景 # 论文 方法类别 核心思路 加速比 提交日期 1 CalibAtt 稀疏注意力(免训练) 离线校准块级稀疏模式 1.58x E2E 3月5日 2 SVG-EAR 稀疏注意力 + 线性补偿(免训练) 误差感知路由 + 聚类质心补偿 1.77-1.93x 3月9日 3 SODA 缓存 + 剪枝(免训练) 敏感度导向的动态加速 SOTA fidelity 3月7日 4 FrameDiT 结构化注意力(需训练) 帧级矩阵注意力 ~Local FA 3月10日 5 VMonarch 结构化注意力(轻量微调) Monarch 矩阵分解 5x attn, 17.5x FLOPs↓ 1月29日 6 SALAD 稀疏 + 线性混合(轻量微调) 门控线性注意力并行分支 1.72x, 90%稀疏 1月23日 7 SLA 稀疏 + 线性融合(微调) 三级权重分类 + 自定义 kernel 2.2x E2E, 13.7x attn 2025.9 (ICLR'26) 8 FastLightGen 蒸馏 + 剪枝 步数+参数同时压缩 4步+30%剪枝 3月2日 9 Diagonal Distillation 自回归蒸馏 对角蒸馏 + 隐式光流 277.3x, 31 FPS 3月10日 二、重点论文深度解读 论文 1:CalibAtt — 校准稀疏注意力加速视频生成 标题:Accelerating Text-to-Video Generation with Calibrated Sparse Attention 作者:Shai Yehezkel, Shahar Yadin, Noam Elata 等 机构:以色列理工 日期:2026年3月5日 arXiv:2603.05503 关键词:稀疏注意力 免训练 离线校准 块级模式 Wan 2.1 Mochi 研究动机 视频 DiT 中的全注意力计算是推理速度的主要瓶颈。已有的稀疏注意力方法要么需要训练(如 SLA、SALAD),要么是在线动态判断每个 token 的重要性(开销大)。作者观察到一个关键现象:大量 token-to-token 连接在不同输入上一致地产生可忽略的注意力分数,且这些模式在不同查询间重复出现。 方法原理 CalibAtt 采用"离线校准 + 在线高效推理"的两阶段策略: 离线校准阶段:在少量参考视频上运行全注意力,统计每一层、每个注意力头、每个扩散时间步的块级(block-level)稀疏模式和重复模式 模式编译:将稳定的稀疏模式编译为优化的注意力操作(类似于"稀疏注意力的 JIT 编译") 在线推理:只计算被选中的输入相关连接,以硬件友好的方式跳过未选中的连接 核心创新 块级粒度:不做 token 级稀疏(开销大),而是以 token block 为单位,兼顾精度和效率 跨输入稳定性:发现稀疏模式对输入不敏感,可以离线固定 层-头-时间步三维校准:不同层/头/时间步的稀疏模式不同,细粒度适配 实验结果 在 Wan 2.1 14B、Mochi 1 及其蒸馏版本上测试 实现 1.58x 端到端加速 在视频生成质量和文本-视频对齐度上优于已有免训练方法 支持多种分辨率 技术脉络 Sparse VideoGen (2024) → Sparse VideoGen2 (2025.5) → CalibAtt (2026.3)。从在线动态稀疏 → 离线校准静态稀疏,核心洞察是"稀疏模式跨输入稳定"。 批判性点评 优势:完全免训练,直接即插即用;离线校准成本低;硬件友好 局限:1.58x 的加速比在本周论文中并不突出;块级粒度可能丢失细粒度信息;对新架构需要重新校准 创新性评分:3/5 — 洞察有价值但方法相对直接 论文 2:SVG-EAR — 无参数线性补偿的误差感知路由 标题:SVG-EAR: Parameter-Free Linear Compensation for Sparse Video Generation via Error-aware Routing 作者:Xuanyi Zhou, Qiuyang Mang, Shuo Yang 等 (UC Berkeley, Ion Stoica 组) 日期:2026年3月9日 arXiv:2603.08982 关键词:稀疏注意力 线性补偿 误差感知路由 聚类质心 免训练 Wan 2.2 HunyuanVideo 研究动机 现有稀疏注意力方法面临两难:(1) 直接丢弃被跳过的注意力块会丢失信息;(2) 用学习型预测器来近似它们又引入训练开销和分布偏移。能否在不训练的情况下恢复被跳过块的贡献? 方法原理 SVG-EAR 的核心洞察:经过语义聚类后,同一块内的 key 和 value 具有高度相似性,可以用少量聚类质心准确概括。 聚类质心补偿:对被跳过的注意力块,用 key/value 的聚类质心做线性(O(N))近似,恢复其对输出的贡献 误差感知路由:传统方法按注意力分数选择需要精确计算的块,但高注意力分数 ≠ 高近似误差。SVG-EAR 用一个轻量探测器估计每个块的补偿误差,选择"误差-成本比"最高的块做精确计算 理论保证:提供了注意力重建误差与聚类质量之间的理论上界 核心创新 误差感知 vs 分数感知:颠覆了传统"高注意力分数 = 重要"的假设,改为"高近似误差 = 需要精确计算" 无参数线性补偿:用聚类质心做 O(N) 补偿,不需要任何训练 帕累托最优:在所有免训练方法中建立了新的帕累托前沿 实验结果 Wan 2.2:1.77x 加速,PSNR 29.759 HunyuanVideo:1.93x 加速,PSNR 31.043 显著优于 Sparse VideoGen2 和 CalibAtt 技术脉络 Sparse VideoGen → SVG2 → SVG-EAR(同一系列的第三代,Ion Stoica / Berkeley 团队的持续推进) 批判性点评 优势:免训练、有理论保证、误差感知路由的思路很优雅 局限:聚类质心计算本身有开销;实际 wall-clock 加速受限于聚类效率;PSNR 不是视频生成的最佳指标 创新性评分:4/5 — 误差感知路由是本周最有洞察的方法论创新 论文 3:SODA — 敏感度导向的动态加速 标题:SODA: Sensitivity-Oriented Dynamic Acceleration for Diffusion Transformer 作者:Tong Shao, Yusen Fu 等 日期:2026年3月7日 arXiv:2603.07057 关键词:缓存 剪枝 敏感度分析 动态规划 免训练 DiT-XL PixArt-α OpenSora 研究动机 特征缓存(caching)和 token 剪枝(pruning)是两种互补的加速手段:缓存加速效率高但影响保真度,剪枝相反。现有方法用固定的启发式策略组合两者,无法捕捉模型对加速操作的细粒度敏感度变化。 方法原理 离线敏感度建模:构建跨时间步、层、模块的敏感度误差模型,量化每个计算单元对缓存/剪枝操作的敏感程度 动态规划优化缓存间隔:以敏感度误差为代价函数,用 DP 求解最优缓存时间点 自适应剪枝:在缓存复用阶段,根据 token 敏感度动态决定剪枝时机和比例 核心创新 敏感度误差建模:不是简单地均匀缓存/剪枝,而是"在最不敏感处缓存,在最不敏感的 token 处剪枝" DP 最优化:缓存间隔不再是超参数,而是通过动态规划自动求解 实验结果 在 DiT-XL/2、PixArt-α、OpenSora 上实现 SOTA 生成保真度 在可控加速比下保真度显著优于 PAB、∆-DiT 等基线 技术脉络 FasterCache (2024) → ∆-DiT (2024) → PAB → SODA (2026.3) 批判性点评 优势:缓存+剪枝的统一框架,敏感度建模理论扎实 局限:离线敏感度分析需要额外推理开销;DP 只优化缓存间隔,未联合优化剪枝策略;仅测试了较小的模型(DiT-XL/2),未在 Wan/HunyuanVideo 等大模型上验证 创新性评分:3.5/5 论文 4:VMonarch — Monarch 矩阵结构化注意力 标题:VMonarch: Efficient Video Diffusion Transformers with Structured Attention 作者:Cheng Liang, Haoxian Chen, Liang Hou 等 (南京大学 + 腾讯) 日期:2026年1月29日 arXiv:2601.22275 关键词:Monarch矩阵 结构化稀疏 交替最小化 FlashAttention 在线熵 5x加速 研究动机 视频 DiT 的注意力模式天然具有高度稀疏的时空结构,但现有稀疏方法(Top-K、局部窗口)要么不灵活,要么丢失全局信息。能否找到一种数学上优雅的方式来表示这些稀疏模式? 方法原理 VMonarch 将视频 DiT 的稀疏注意力模式建模为 Monarch 矩阵 —— 一类具有灵活稀疏性的结构化矩阵。 时空 Monarch 分解:将全注意力矩阵分解为帧内(空间)和帧间(时间)两组 Monarch 因子,分别捕捉空间和时间相关性 交替最小化:通过交替优化两组因子来逼近原始全注意力 重计算策略:解决交替最小化不稳定导致的伪影问题 在线熵算法:融入 FlashAttention 的在线熵计算,支持长序列高效更新 核心创新 Monarch 矩阵在视频 DiT 中的首次应用:优雅地统一了稀疏和结构化的优势 在线熵 + FlashAttention 融合:使得 Monarch 矩阵更新在长序列上也可行 实验结果 注意力 FLOPs 减少 17.5 倍 注意力计算加速 5 倍以上 在 VBench 上轻量微调后质量与全注意力相当 90% 稀疏度下超越所有 SOTA 稀疏注意力方法 技术脉络 Monarch Mixer (2023) → Monarch in LLM → VMonarch (视频 DiT 首次应用) 批判性点评 优势:数学上最优雅的方案;17.5x FLOPs 减少是本周最极端的数字;与 FlashAttention 兼容 局限:交替最小化的收敛性依赖初始化;需要轻量微调(非完全免训练);实际 wall-clock 加速(5x)远小于理论 FLOPs 减少(17.5x),说明实现上有瓶颈 创新性评分:4.5/5 — 本周最具理论深度的工作 论文 5:SLA — 稀疏-线性注意力融合 标题:SLA: Beyond Sparsity in Diffusion Transformers via Fine-Tunable Sparse-Linear Attention 作者:Jintao Zhang 等 (清华 + Berkeley) 日期:2025年9月28日(ICLR 2026 Oral) arXiv:2509.24006 关键词:稀疏注意力 线性注意力 融合 自定义GPU kernel 95%计算减少 ICLR 2026 研究动机 注意力权重可以分为两部分:少量大权重(高秩)和大量小权重(低秩)。这天然暗示:对大权重用稀疏注意力(O(N²) 但只算少量),对小权重用线性注意力(O(N))。 方法原理 三级分类:将注意力权重分为 Critical(O(N²) 精确计算)、Marginal(O(N) 线性注意力)、Negligible(跳过) 融合 GPU kernel:将稀疏和线性注意力的计算融合到单个 GPU kernel 中,支持前向和反向传播 轻量微调:仅需少量微调步就能适配 核心创新 稀疏+线性的系统性融合:不是简单的 fallback,而是基于权重分布的最优分配 自定义 GPU kernel:工程实现极其扎实,直接转化为实际加速 实验结果 注意力计算减少 95%(20 倍) 注意力加速 13.7 倍 端到端加速 2.2 倍(Wan 2.1-1.3B) 生成质量无损 技术脉络 稀疏注意力 + 线性注意力两条独立技术路线 → SLA 首次统一融合(ICLR 2026 Oral) 批判性点评 优势:ICLR 2026 Oral,学术认可度最高;2.2x E2E 加速是免训练之外的最佳实际数字;自定义 kernel 可直接落地 局限:需要微调(虽然很轻量);目前只在 1.3B 模型上测试,14B 模型的效果未知;kernel 需要针对不同硬件调优 创新性评分:4.5/5 论文 6:SALAD — 高稀疏度线性注意力微调 标题:SALAD: Achieve High-Sparsity Attention via Efficient Linear Attention Tuning for Video Diffusion Transformer 作者:Tongcheng Fang 等 (清华 + 腾讯) 日期:2026年1月23日 arXiv:2601.16515 关键词:线性注意力 门控机制 高稀疏度 轻量微调 2000样本 研究动机 免训练稀疏注意力受限于有限的稀疏度(通常 50-70%),而训练型方法需要大量数据和计算。能否用极轻量的微调达到极高稀疏度? 方法原理 双分支并行:在稀疏注意力旁边添加一个轻量线性注意力分支 输入依赖门控:用门控机制动态平衡两个分支的贡献 极轻量微调:仅需 2000 个视频样本和 1600 步训练 实验结果 90% 稀疏度,1.72x 推理加速 生成质量与全注意力基线相当 批判性点评 思路与 SLA 类似但更轻量;微调效率极高(2000 样本);但 1.72x 加速低于 SLA 的 2.2x 创新性评分:3.5/5 论文 7:FastLightGen — 步数 + 参数同时压缩 标题:FastLightGen: Fast and Light Video Generation with Fewer Steps and Parameters 作者:Shitong Shao, Yufei Gu, Zeke Xie 日期:2026年3月2日 arXiv:2603.01685 关键词:蒸馏 剪枝 步数压缩 参数压缩 HunyuanVideo WanX 研究动机 以往的加速研究要么减少采样步数(蒸馏),要么减少模型参数(剪枝),但从未同时压缩两者。 方法原理 FastLightGen 的核心:构建一个"最优教师模型",在协同框架中同时蒸馏步数和参数。 协同蒸馏框架:同时优化步数减少和参数剪枝 最优教师构建:教师模型本身经过优化,以最大化学生模型的性能 实验结果 4 步采样 + 30% 参数剪枝 = 最佳视觉质量(在约束推理预算下) 在 HunyuanVideo-ATI2V 和 WanX-TI2V 上优于所有竞争方法 批判性点评 首次探索步数+参数的联合压缩,填补了研究空白 但 30% 剪枝比较保守;缺少与纯蒸馏方法的详细对比 创新性评分:3.5/5 论文 8:Diagonal Distillation — 对角蒸馏实现流式视频生成 标题:Streaming Autoregressive Video Generation via Diagonal Distillation 作者:Jinxiu Liu 等 (HKUST, Ming-Hsuan Yang) 日期:2026年3月10日 arXiv:2603.09488 关键词:自回归 蒸馏 流式生成 光流建模 277x加速 31 FPS 研究动机 扩散蒸馏将多步模型压缩为少步变体,但现有方法主要针对图像设计,忽略了视频的时间依赖性,导致运动不连贯和长序列误差累积。 方法原理 对角蒸馏:不同于传统的逐 chunk 独立蒸馏,Diagonal Distillation 沿"视频 chunk × 去噪步"的对角线方向进行蒸馏 非对称生成策略:前面的 chunk 用更多步、后面的 chunk 用更少步。后面的 chunk 可以继承前面已充分处理的外观信息 隐式光流建模:在严格步数约束下保持运动质量 核心创新 对角蒸馏:沿时间-步数对角线操作,充分利用时间上下文 非对称步数分配:打破"每个 chunk 步数相同"的假设 曝光偏差缓解:将训练时的噪声条件与推理时对齐 实验结果 5 秒视频 2.61 秒生成(31 FPS) 相比原始模型 277.3 倍加速 运动连贯性和长序列质量显著优于图像蒸馏方法 批判性点评 优势:277x 是本周最震撼的加速数字;流式生成对实时应用极其重要 局限:目前仅适用于自回归视频模型;生成质量与原始多步模型仍有差距;FPS 数字的分辨率条件未详细说明 创新性评分:4/5 论文 9:FrameDiT — 帧级矩阵注意力 标题:FrameDiT: Diffusion Transformer with Frame-Level Matrix Attention for Efficient Video Generation 作者:Minh Khoa Le 等 日期:2026年3月10日 arXiv:2603.09721 关键词:帧级注意力 矩阵注意力 时空结构 Local Factorized 研究动机 现有方法面临 Full 3D Attention(强但贵)vs Local Factorized Attention(快但丢失全局信息)的两难。 方法原理 Matrix Attention:将整帧作为矩阵处理,通过矩阵原生操作生成 Q/K/V 帧间注意力:在帧级别而非 token 级别做跨帧注意力,保持全局时空结构 FrameDiT-H:混合 Matrix Attention + Local Factorized Attention,同时捕捉大运动和小运动 实验结果 多个视频生成 benchmark 上达到 SOTA 效率与 Local Factorized Attention 相当 批判性点评 帧级注意力的粒度介于 Full 3D 和 Local Factorized 之间,是一个有趣的中间地带 但"矩阵注意力"的具体实现细节(矩阵原生操作是什么?)缺乏清晰的数学定义 创新性评分:3/5 三、横向对比分析 3.1 方法分类体系 本周的 9 篇论文可以按 "是否需要训练" 和 "加速策略" 两个维度分类: 免训练 轻量微调 训练/蒸馏 ┌─────────┐ ┌─────────┐ ┌─────────┐ 稀疏注意力 │CalibAtt │ │ SALAD │ │ SLA │ │SVG-EAR │ │VMonarch │ │ │ ├─────────┤ ├─────────┤ ├─────────┤ 缓存+剪枝 │ SODA │ │ │ │ │ ├─────────┤ ├─────────┤ ├─────────┤ 蒸馏+压缩 │ │ │ │ │FastLight│ │ │ │ │ │DiagDist │ ├─────────┤ ├─────────┤ ├─────────┤ 结构化注意力 │ │ │ │ │FrameDiT │ └─────────┘ └─────────┘ └─────────┘ 3.2 性能对比 方法 注意力加速 端到端加速 需要训练? 测试模型 质量保持 CalibAtt - 1.58x 否 Wan 2.1 14B, Mochi ★★★★ SVG-EAR - 1.77-1.93x 否 Wan 2.2, HunyuanVideo ★★★★ SODA - 可控 否 DiT-XL, PixArt-α, OpenSora ★★★★★ VMonarch 5x - 轻量微调 VBench ★★★★ SALAD - 1.72x 2000样本 - ★★★★ SLA 13.7x 2.2x 少量微调 Wan 2.1 1.3B ★★★★★ FastLightGen - 显著 蒸馏 HunyuanVideo, WanX ★★★★ Diagonal Dist. - 277.3x 蒸馏 自回归模型 ★★★ FrameDiT ~FA级 ~FA级 训练 多个benchmark ★★★★ 3.3 技术路线演进 本周的论文清晰地展现了四条技术路线的演进: 路线 A:免训练稀疏注意力 核心思想:发现并利用注意力的天然稀疏性 演进:Token-level Top-K → Block-level 静态模式 (CalibAtt) → 误差感知动态路由 (SVG-EAR) 加速上限:~2x(受限于稀疏度无法无限提高) 路线 B:稀疏 + 线性注意力融合 核心思想:对不同重要性的注意力权重使用不同计算策略 演进:纯稀疏 / 纯线性 → 并行双分支 (SALAD) → 融合 kernel (SLA) → Monarch 结构化 (VMonarch) 加速上限:~2-5x(取决于 kernel 效率) 路线 C:缓存 + 剪枝 核心思想:利用扩散过程中相邻时间步的特征相似性 演进:均匀缓存 → 启发式组合 → 敏感度导向 DP 优化 (SODA) 加速上限:~2-3x(缓存复用比例有限) 路线 D:蒸馏 + 压缩 核心思想:用小模型/少步数逼近大模型/多步数 演进:步数蒸馏 → 参数剪枝 → 联合压缩 (FastLightGen) → 对角蒸馏 (Diagonal Distillation) 加速上限:100x+(但质量损失更大) 3.4 关键洞察与趋势 免训练方法的天花板在 ~2x:CalibAtt (1.58x) 和 SVG-EAR (1.93x) 代表了免训练稀疏注意力的当前上限。突破需要引入轻量训练。 稀疏 + 线性融合是最佳平衡点:SLA 通过自定义 kernel 实现 2.2x E2E 加速且质量无损,是目前注意力加速的最优解。ICLR 2026 Oral 的认可也说明了这一点。 蒸馏方法的加速比远超注意力优化:Diagonal Distillation 的 277x 说明,如果能接受一定质量损失,蒸馏是最强力的加速手段。但注意力优化的优势是"质量无损"。 多种方法可叠加:注意力优化 + 蒸馏可以叠加使用。CalibAtt 已在蒸馏模型上验证有效。理论上 SLA + 步数蒸馏可能实现 5-10x 无损加速。 Wan 和 HunyuanVideo 成为标准测试平台:本周几乎所有论文都在这两个模型上测试,说明它们已成为视频生成的事实标准。 从算法到系统的全栈优化:SODA 的序列并行推理提醒我们,纯算法优化之外,系统级优化(多 GPU 并行、算子融合等)同样重要。 四、总结与展望 本周最值得关注的 3 篇 SLA (ICLR 2026 Oral):稀疏-线性融合的里程碑工作,自定义 kernel 的工程深度令人印象深刻 SVG-EAR:误差感知路由的洞察非常深刻,免训练方法的新标杆 VMonarch:Monarch 矩阵的引入为结构化注意力开辟了全新方向 未来研究方向预判 注意力优化 + 蒸馏的联合框架:将 SLA/SVG-EAR 与 FastLightGen/Diagonal Distillation 结合 更大规模模型验证:SLA 仅在 1.3B 上测试,14B+ 模型上的表现待验证 长视频生成的特化优化:随着视频长度增长到分钟级,注意力优化的重要性进一步凸显 硬件协同设计:自定义 kernel(SLA)和结构化矩阵(VMonarch)需要与硬件特性深度适配 人工智能炼丹师 整理 | 2026-03-14