搜索到
6
篇与
多模态理解
的结果
-
 中文场景下的CLIP图文预训练 1. 写在前面 被广泛使用的CLIP模型,采用英文描述和图片对数据集(WebImageText 400M),进行对比学习训练,限制了其在中文场景下的应用。例如,在文生图应用中,国外开源模型Stable Diffusion需要采用英文作为输入,要支持中文描述生成图片得先翻译为英文。此外利用英文语料库训练的模型,对于【红烧狮子头、佛跳墙、对联和中文的成语、历史典故等】中文语境理解不够 在中文场景下的图文理解,近期也有相应的算法提出,包括智源的AltCLIP、阿里的ChinseCLIP、IDEA研究院的Taiyi、Wenlan、Wukong、R2D2等。这些算法各有优劣,本文将对上述算法和相关的数据集进行总结对比。 2. 中文-图文数据集 数据集 说明 机构 下载链接 WuKong 100M 数据集大小100M 华为 https://wukong-dataset.github.io/wukong-dataset/ Zero-Corpus 开源数据集大小23M(共250M) ,通过用户CTR行为数据进行过滤匹配的图文对 360 https://zero.so.com/index.html Laion5B-CN 包含多语言的图文数据,其中中文约143M LAION https://laion.ai/blog/laion-5b/ M6-Corpus 60M 阿里 数据未开源 TaiSu 166M 中科院自动化所 https://github.com/ksOAn6g5/TaiSu 3. 现有中文CLIP综合对比 多数的中文CLIP均采用固定图像侧模型参数,只训练文本Encoder的方法。为进一步提升性能,ChinseCLIP 采用两阶段训练方案:先只训练文本Encoder,再联合训练图像Encoder+文本Encoder; AltCLIP也采用两阶段训练方案: 利用模型蒸馏,学习不同语种之间的文本语义对齐,再利用图文对对比学习,Finetune文本Encoder。 多数方法虽然提升了模型在中文数据上的指标,但是同时在英文数据上的性能(zero-shot 检索任务)却下降了。截止到目前(2023/04),AltCLIP方法能够在中文和英文数据集上均取得SOTA的结果。 算法 开源日期 训练集 算法概括 Wukong-CLIP 2022-02 Wukong(100M/500M) 冻结图像encoder(ResNet50/VIT/Swin), 只训练文本Encoder,对比学习损失参照FILIP的方式学习细粒度的文本和图像块对齐 Taiyi-CLIP 2022-09 Wukong(100M)+Zero(23M) 基于OpenCLIP,冻结视觉编码器并且只微调语言编码器 ChinseCLIP 2022-11 LAION-CN(108M)+Wukong(72M)+翻译数据(20M, Visual Genome/MSCOCO) 基于OpenCLIP,两阶段训练方案: 1) 先Finetune文本Encoder2) 再结合ImageEncoder联合训练; 模型的缺点: 在英文任务上的指标大幅下降 AltCLIP 2022-12 Wudao + LAION 基于XLM-R文本Encoder+OpenCLIP图像Encoer,两阶段训练方案: 1) 先只是使用平行语料文本(相同含义的中英文数据)来进行蒸馏(平行语料相对于图文对更容易获取且数量更大)2) 再使用少量的2M中/英图像-文本对来训练文本编码器(图像侧固定)
中文场景下的CLIP图文预训练 1. 写在前面 被广泛使用的CLIP模型,采用英文描述和图片对数据集(WebImageText 400M),进行对比学习训练,限制了其在中文场景下的应用。例如,在文生图应用中,国外开源模型Stable Diffusion需要采用英文作为输入,要支持中文描述生成图片得先翻译为英文。此外利用英文语料库训练的模型,对于【红烧狮子头、佛跳墙、对联和中文的成语、历史典故等】中文语境理解不够 在中文场景下的图文理解,近期也有相应的算法提出,包括智源的AltCLIP、阿里的ChinseCLIP、IDEA研究院的Taiyi、Wenlan、Wukong、R2D2等。这些算法各有优劣,本文将对上述算法和相关的数据集进行总结对比。 2. 中文-图文数据集 数据集 说明 机构 下载链接 WuKong 100M 数据集大小100M 华为 https://wukong-dataset.github.io/wukong-dataset/ Zero-Corpus 开源数据集大小23M(共250M) ,通过用户CTR行为数据进行过滤匹配的图文对 360 https://zero.so.com/index.html Laion5B-CN 包含多语言的图文数据,其中中文约143M LAION https://laion.ai/blog/laion-5b/ M6-Corpus 60M 阿里 数据未开源 TaiSu 166M 中科院自动化所 https://github.com/ksOAn6g5/TaiSu 3. 现有中文CLIP综合对比 多数的中文CLIP均采用固定图像侧模型参数,只训练文本Encoder的方法。为进一步提升性能,ChinseCLIP 采用两阶段训练方案:先只训练文本Encoder,再联合训练图像Encoder+文本Encoder; AltCLIP也采用两阶段训练方案: 利用模型蒸馏,学习不同语种之间的文本语义对齐,再利用图文对对比学习,Finetune文本Encoder。 多数方法虽然提升了模型在中文数据上的指标,但是同时在英文数据上的性能(zero-shot 检索任务)却下降了。截止到目前(2023/04),AltCLIP方法能够在中文和英文数据集上均取得SOTA的结果。 算法 开源日期 训练集 算法概括 Wukong-CLIP 2022-02 Wukong(100M/500M) 冻结图像encoder(ResNet50/VIT/Swin), 只训练文本Encoder,对比学习损失参照FILIP的方式学习细粒度的文本和图像块对齐 Taiyi-CLIP 2022-09 Wukong(100M)+Zero(23M) 基于OpenCLIP,冻结视觉编码器并且只微调语言编码器 ChinseCLIP 2022-11 LAION-CN(108M)+Wukong(72M)+翻译数据(20M, Visual Genome/MSCOCO) 基于OpenCLIP,两阶段训练方案: 1) 先Finetune文本Encoder2) 再结合ImageEncoder联合训练; 模型的缺点: 在英文任务上的指标大幅下降 AltCLIP 2022-12 Wudao + LAION 基于XLM-R文本Encoder+OpenCLIP图像Encoer,两阶段训练方案: 1) 先只是使用平行语料文本(相同含义的中英文数据)来进行蒸馏(平行语料相对于图文对更容易获取且数量更大)2) 再使用少量的2M中/英图像-文本对来训练文本编码器(图像侧固定) -
生成内容真实度判别调研 & 模型选型 1. 背景概述 调研出发点: 利用判别模型对生成内容进行真假打分,根据模型输出属于“真”类的得分进行排序,可以筛选出生成“质量”更高的内容 任务难点: 简单的二分类任务(真假判别),泛化性能不足(没学到期望的关键信息) 简单整图二分类模型的解释性不强。如果能够在空间上“检测”到不真实部分的位置,则模型的可解释性更强 本文主要围绕DeepFake相关工作和近期文本/图像生成模型和强化学习结合的Reward函数设计两方面展开调研 2. 相关工作 2.1 真假图像鉴别 2.1.1 粗暴二分类方案 【CVPR 2020】【Adobe Research】CNN-generated images are surprisingly easy to spot... for now Motivation:提升真假鉴别器在不同数据集上的泛化性,实验分析影响模型泛化性的因素 Method & Results: 模型结构:利用ImageNet预训练的ResNet50进行真假鉴别二分类训练 数据增广:Gaussian blur、JPEG压缩的数据增广,提升模型在不同数据集下的泛化性能 定性分析: 鉴别器不能稳定表征图像的真实度/虚假度,在部分数据集上可观测到规律 4. 生成图片 vs 真实图片频域差异:大部分生成图片在频域有棋盘效应(low-level CNN artifacts) 5. 在PS结果上的泛化性:模型在Photoshope处理过的数据集上预测结果近乎随机 2.1.2 关注局部细节的鉴别方法 【CVPR 2021】【Microsoft Cloud AI】Multi-attentional Deepfake Detection Motivation:真假图片分类和Fine-grained图片分类相似,更关注图像的局部细节,而不是整体轮廓 or 背景语义信息。借鉴Fine-grained classification中的part-based方法提升细节鉴别能力 Method & Results:采用浅层纹理特征 & 深层语义特征融合的方式,进行二分类网络训练 局部边缘纹理增强模块(Texture enhancement block): 输入浅层特征Feature map,减去模糊(pooling)后的Feature mAP得到边缘纹理 空间局部注意力模块[Attnetion Module] & Bilinear Attention Pooling:输入高层语义特征,经过1x1卷积获得M个不同的Attention Map(Fk),利用这些注意力引导浅层&深层特征 增强注意力多样性: 基于注意力的显著性区域模糊AGDA(Attention Guided Data Augmentations):I′ = I × (1 − A) + Id × A (Id为高斯模糊图像,A为随机一张attention MAP) 注意力特征图metric learning约束(Regional Independence Loss):同一个注意力图关注区域特征相近,不同注意力图关注区域特征远离 【CVPR 2022】【Youtu Lab, Tencent】End-to-End Reconstruction-Classification Learning for Face Forgery Detection Motivation:当训练集中Fake类别图像分布不够丰富时(Fake图片的种类通常是多样且日益增长),判别式模型的泛化性能存在问题 Method & Results:通过生成式模型AutoEncoder进行像素级重建,学习真实图像的数据分布 模型结构优化: 像素级AutoEncoder重建(只对真实样本进行) & 重建误差注意力引导 在多个图像尺度下进行Encoder、Decoder之间的信息聚合: 度量学习损失优化:只约束真实样本特征之间尽可能接近(不同方法生成样本分布差异大),约束真假图像之间距离远离 模型泛化能力验证:训练不做数据扰动,测试时进数据增广,验证模型性能 2.1.3 基于频域的检测方法 【ECCV 2020】【SenseTime】Thinking in Frequency: Face Forgery Detection by Mining Frequency-aware Clues Motivation: 生成图像的“伪影”在频域更为明显,通过引入频域特征,提升模型鉴别能力;当图像被JPEG压缩后,伪影在像素空间上不显著,但在频域响应中可见 Method & Results: 论文方法整体还是一个二分类的框架,为了能够充分利用频域信息,作者采用了FAD提取空间域特征,LFS提取频域特征,最后再进行两类特征融合。 Frequency-aware 空间域特征(FAD):利用DCT将输入图像转换到频域,在频域进行高通、低通、和带通滤波,每个频带的滤波结果转换回空间域之后,就实现了图像分解,图像分解之后再进行CNN特征提取。 Local Frequency Statistics (LFS频域特征):利用滑动窗口DCT,对空间局部快进行频域分布统计特征 LFS 与FAD虽然都利用了频域信息,但是LFS是显式地以频域幅值作为特征,而FAD则通过DCT反变换回空间域再进行CNN特征提取。局部窗口统计特征 & 空间像素特征具有平移不变形,所以能适用CNN。(不直接在整图的频域上使用CNN) two-stream融合模块:Cross Attnetion 进行两类特征融合 模型优点 & 实验验证:在低画质图像上(压缩),模型的性能优越 【CVPR 2021】【Kuaishou】Frequency-aware Discriminative Feature Learning Supervised by Single-Center Loss for Face Forgery Detection Motivation: 1)基于softmax的分类损失没有约束类内距离紧凑 & 类间距离尽可能远离,为了实现这一目标提升鉴别器模型的泛化能力,作者提出针对真假二分类的度量学习损失函数;2)频域与像素空间域特征互补,提升精度 Method & Results: 模型整体流程:输入RGB图像,分别提取空间像素域和频域特征,对融合后的特征进行Softmax loss和Single-Center Loss两种损失函数进行监督: 频域特征提取:与JPEG压缩的方法类似,将RGB-〉YCbCr后,对局部块(8*8)进行DCT变换,并合并相同频率系数到当个channel(局部块 & reshape等操作和F3Net相似) Single-Center Loss:最小化真实图像特征与Natural(真实图像)类中心之间的距离 & 最大化,最大化每个生成图像与Natural类别中心之间的相对距离 模型效果验证: 2.2 生成内容排序 2.2.1 文本生成 【InstructGPT】【OpenAI】Training language models to follow instructions with human feedback Reward Model方法:对于一个prompt生成N个结果,让标注员对生成内容进行排序。对于一条排序好的标注数据,选择组样本对,并构建pairwise网络,学习对选择的两个生成内容进行质量高低判断。不做绝对打分而做排序的原因:排序标注更容易达成一致意见,标准更统一,而打绝对分数标注更困难(进而导致标注质量低,模型训练困难)。 2.2.2 图片生成 【Google】 Aligning Text-to-Image Models using Human Feedback Reward Function:学习文本与生成图像之间的匹配程度,采用0/1二分进行监督(背景/计数/颜色三方面综合考量) 模型输入:prompt T + 生成图像 I 模型输出:利用clip的文本 & 视觉 encoder分别提取文本和图像特征,经过两层MLP直接输出匹配度 监督目标:监督信号包含有监督和自监督两种 有监督:Reward模型输出的匹配度与人工标注的0/1匹配值,进行MSEloss监督 自监督:随机采样N个文本与生成图像I计算匹配度,最后得到N+1个匹配度score,进行CrossEntropy损失函数监督 3. 方案选型 3.1 网络结构选型 3.2 监督目标选型 4. 参考文献 https://github.com/Daisy-Zhang/Awesome-Deepfakes-Detection https://docs.qq.com/doc/DVG9pRHBFTUxYa0t1?&u=b0613c6debd74375ab98960a2d73d708
-
公开音频数据集和语音预训练模型总结 开源数据集 数据集 说明 Google-AudioSet 2084k, 527个类别, youtube视频 Youtube-100M 100M Youtube视频,根据标题/描述/评论自动生成的标签,标签集合约3w WeneSpeech 中文1w小时+音频数据集, 包括有声书、解说、纪录片、电视剧、访谈、新闻、朗读、演讲、综艺和其他等10大场景 VGG-Sound short clips of audio sounds, 200k个Youtube视频, 310个类别 LibriSpeech Large-scale (1000 hours) corpus of read English speech Libri-Light open-source audio books from the LibriVox project GigaSpeech audiobooks, podcasts and YouTube VoxPopuli multilingual corpus, 23种语言,100k小时 开源预训练模型 模型 训练数据 备注 Vggish YouTube-100M 2017年 腾讯游戏开源wav2vec2.0 & hubert WeneSpeech 2021年 FaceBook data2vec LibriSpeech 2022年 MSRA WavLM Libri-Light, GigaSpeech, VoxPopuli 2021年
-
2022年微信大数据比赛(多模态短视频分类)总结 写在前面 今天(2022.09.17), 微信大数据比赛进行了现场决赛答辩。由于工作内容和比赛比较相关,所以一直有关注。简单总结下听完线上现场答辩直播后的一些感受。近年来随着短视频的发展,多模态视频分类任务变得越来越火,多模态分类算法方案从最开始的: 多模态特征提取后简单concat拼接的baseline方案,演进到目前主流采用在大规模数据下进行预训练方式,来充分利用无标注数据获取更好的特征表示和将不同模态特征对齐,参赛选手都是基于预训练+Finetune方式来做的,但答辩现场给我影响最深刻的就是,评委张正友老师谈到的: 选手针对赛题本身问题做的优化太少。我们在做算法优化的时候,应该优先去做哪些算法优化点, 我相信这也是算法工程师经常遇到的问题。本文主要围绕这个谈谈个人的想法,最后总结下比赛中多模态分类里的一些上分优化点。 从数据分析问题出发还是“无脑堆好模型”? 这道赛题的难点如果去做数据分析,我们大概率会发现是这些问题:1) 数据类别分布不均衡;2) ASR/OCR/Title文本数据存在噪声(识别不准确 + 标签党视频文本不匹配等等),直接做对视频/文本对比学习可能噪声大;3)ASR/OCR相比较于标题而言噪声更大,如何区分处理不同类型的文本;4)标签体系是层次的,包括一级分类和二级分类,做层次分类可能对比模型精度能够有提升 5)标注数据GT是有噪声的, 如何做带噪学习训练,和标签数据清洗等方面。6) 如何利用大量无标注数据。这类问题每个都能找到很多论文来解决,但到底最后能对最终的评测指标能有多少提升却很难准确预估。 比赛的第一名GDY的方案,最大的不同的地方是利用单流/双流等差异性足够大的模型做集成,最后再利用模型蒸馏的想法将未标注的数据集利用起来。想法其实也很简单,利用好而不同的模型集成和模型蒸馏也是教科书里面会涉及的知识点,但就是这拉开了和其他选手之间的比分差距。对于数据分析能表现出来的问题,没有在最终方案中体现出来。比如数据不均衡问题,第一名没有做特殊处理优化,只是简单地使用了训练数据类别重采样,和利用蒸馏得到的伪标签样本进行类别平衡。 所以,这就引发我思考: 我们在做算法优化的时候,应该优先去做哪些算法优化。基于数据分析问题出发,还是直接无脑把先各种最好的模型堆叠起来,去快速不断尝试刷新指标。如果基于数据分析到的问题来解决问题,我们可能会采取以下一些方案: 比如标注数据GT带噪,可能最无脑的方式是顾一大批人,来人工把数据智能清洗一遍(有钱好办事) 更高效一点的方式,是利用聚类算法,基于规则对数据进行清洗 偏学术的做法,基于带噪训练的框架, 选择对噪声更鲁邦的损失函数等 这些针对具体问题出发的解决方法和“选择一个更好的模型”,那个应该优先做?对于选手来说,在限定时间的比赛阶段来看,能够快速做模型迭代是很重要的。对在岗工程师而言,如果抓不住主要矛盾,而导致项目不能在deadline前完成也不好交差。 一些想法(欢迎留言讨论) 我觉得 数据分析 + 堆好模型两个都很重要,在不同的时期,需要给两者分配不同的权重 1.项目初期: 数据分析很重要,把事情做对而不是做最好。在工业界做算法开发,不像参加比赛,已经有人给我们准备好了训练和测试集。这些都需要我们自己构建(或外包标注团队),标注数据很可能有错标/缺失的问题,这个时候我们需要结合数据分析把数据做对,而不是疯狂堆好模型。不同的模型在有问题的数据上的测试结果可能就是随机数,不可信。 2.项目中期: 抓住主要矛盾,优先做最大投入产出比的事。 这个时候不能陷入到细节中,要有大局意识,找到投入产出比最大的方面进行优化。但如何找到主要矛盾也是门学问,我觉得主要依赖两点: 足够的经验积累和有效的数据分析。在比赛中,我们无法通过数据分析提前知道模型蒸馏是不是投入产出比最大的优化点,这部分只能试,但试的前提的有自己的insight,知道为什么试这个方案,这个方案预期能带来哪些增益,这就依赖于我们历史积累的经验和读过的论文来大致估计这部分的增益。数据分析也是项目中期需要特别关心的。包括混淆矩阵/PR指标/具体badcase归类等。 3.项目后期: 问题针对性优化,到这个时候已经基本满足业务需求了,基本是精益求精的时候,就更需要结合具体问题逐个击破(对于业务而言,这个时候再做任何模型优化,可能投入产出比并不大~) 多模态分类算法优化点总结 下面主要从数据处理、模型选取、优化tricks、模型集成等方面归纳总结下方案 1.数据处理: 视频抽帧在训练阶段随机采样,增加训练的多样性 文本可以采用分词而不是分字的方式,缓解文本长度过长问题,roberta-base-word-chinese-cluecorpussmall 2.模型选取: 模型选取,能选large就不选base,选择预训练数据集大和模型规模大的模型(clip-large) R2D2 参考BEIT3等 3.优化tricks防止过拟合: EMA模型平均,这个按经验一般有1%左右提升 FGM 文本对抗训练 Finetune时加预训练任务防止过拟合 RDrop: 一致性约束 4.模型集成: 好而不同,选择差异性大的好模型进行集成(单流&双流), 有利于模型蒸馏; 只用单个模型预测的伪标签,自己学自己,提升效果可能不理想 5.模型加速 TensorRT量化,可用选择对backbone模型进行量化,具体的分类模型在量化后的特征上进行训练,以保证精度不降的情况下提升模型推理效率 FasterTransformer Fp16推理 6.预训练任务选择 选手基本都是基于后验评测指标来综合考虑是否加mlm/mfm/vtm等预训练任务 参考链接 复赛结束后微信群内参赛选手讨论内容
-
Video Understanding Dataset 1. 视频理解数据集概览 2. 数据集详情介绍 SoccerNet HVU ICCV 2019, tag list THUMOS14 THUMOS Challenge 2014 训练集:UCF101,101种动作类别,共13320剪辑的视频片段;验证集:1010未剪辑视频,其中200个有时序标注(3007个行为段,包含20类行为);测试集:1574未剪辑视频,其中213个有时序标注(3358个行为段)。 ActivityNet CVPR2015 包含分类、检测任务,包含200个动作类别,20000多视频(训练10024+验证4926+测试5044)。 Charades 2016 主要包含9848个未剪辑的室内视频(训练7985+1863测试),包含157个类别及267不同的人物,每段视频大约30秒。 AVA 2018 包含430个15分钟电影剪辑片段及标注80类动作。有386,000个标记的片段,614,000个标记的边界框和81,000条人迹。 总共有158万个带有标签的动作,每个人经常有多个标签。 MovieNet ECCV2020 Moments-in-time ICCV2019 Opps CVPR2020 异常动作时间定位数据集 3. 参考文献 视频理解公开数据集
-
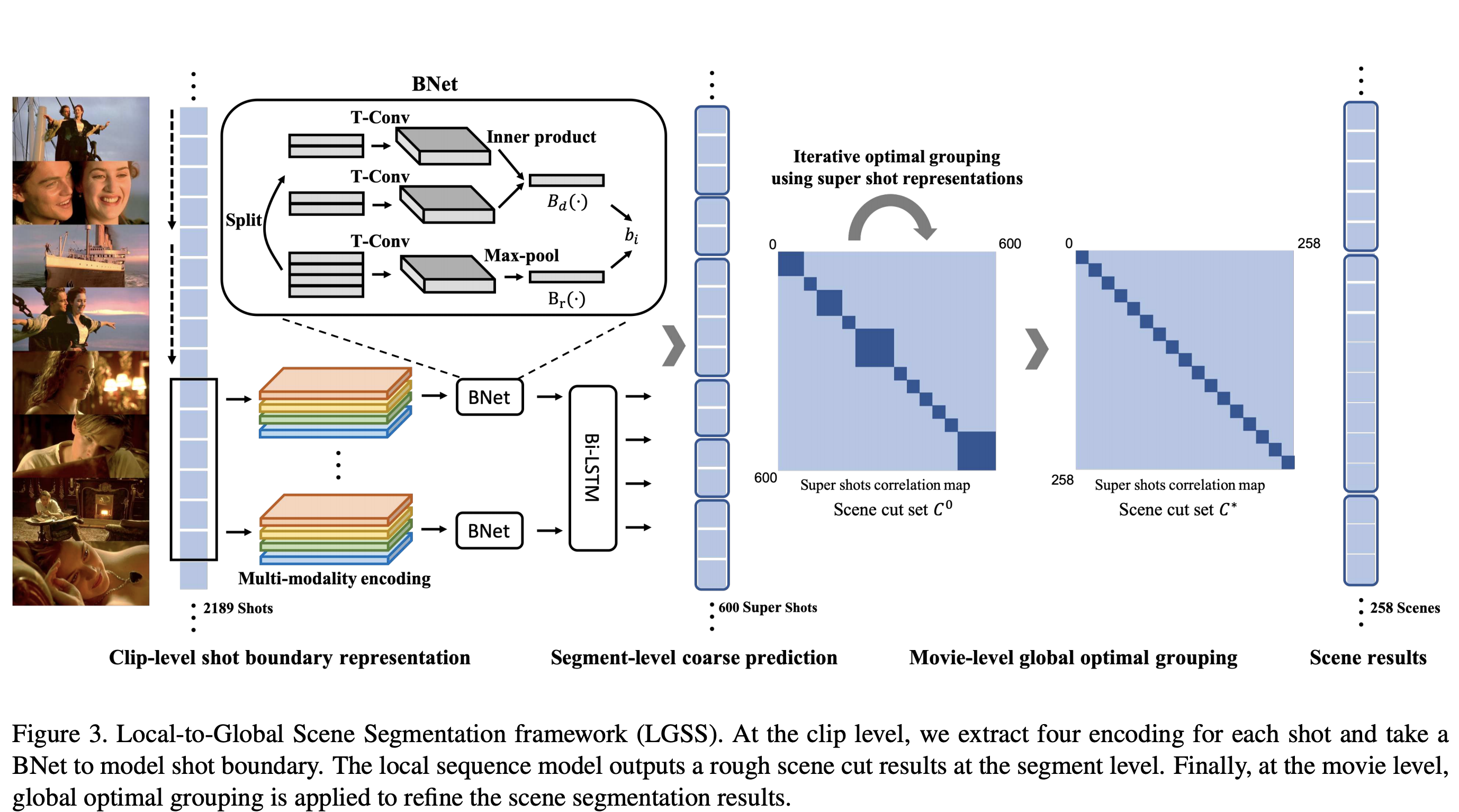
视频时序切分 将视频在时序维度(镜头 + 场景)进行理解, 相关公开数据集和benchmark:SoccerNet-v2、 Kinetics-GEBD、MovieNet ViTT-AACL2020 1. 镜头分割(Shot Boundray Segmentation) 镜头切分benchmark: ClipShots、TRECVID、SoccerNet-v2 1.1 TransNet 1.2 TransNet V2 1.3 DSBD 2. 场景分割(Scene Boundray Segmentation) 2.1 SceneSeg A Local-to-Global Approach to Multi-modal Movie Scene Segmentation [CVPR 2020] 论文简介:提出一个场景切分数据集MovieNet(380个电影),此外提出了一个局部到全局的场景切分算法 Github Code 算法整体流程: 镜头切分,公开的源代码采用了传统方法做镜头切分,可以考虑用深度学习方法做优化,如TransNet等 对每个镜头提取多个模态特征(动作、地点、语音等维度) 进行局部到全局的特征聚合,利用BNet(boundary Network)实现局部的特征融合 a. Clip-level: BNet由两个部分构成: 通过内积建模镜头之间(4个镜头)的差异,通过temporal conv + max pooling建模镜头之间的联系,二者concat b. Segment-level: 通过bi-LSTM实现序列到序列的功能,其中序列长度选取10(远小于镜头数目,为了减少内存消耗) c. global optimal grouping: 通过过动态规划,实现后处理优化(优点:考虑了所有镜头特征,考虑了长时的上下文依赖,缺点: 没有能够实现端到端的优化,与前面的模型时独立的), 具体细节参考StoryGraph 2.2 Shot Type Classification A Unified Framework for Shot Type Classification Based on Subject Centric Lens[ECCV2020] 镜头拍摄风格识别 Deep Relationship Analysis in Video with Multimodal Feature Fusion [ACM MM 2020] 多模态场景理解 2.3 自监督预训练 Shot Contrastive Self-Supervised Learning for Scene Boundary Detection [CVPR2021] Amazon BaSSL: Boundary-aware Self-supervised Learning for Video Scene Segmentation UBoCo : Unsupervised Boundary Contrastive Learning for Generic Event Boundary Detection Scene Consistency Representation Learning for Video Scene Segmentation 3. 事件分割(Event Segmentation) Generic Event Boundary Detection: A Benchmark for Event Segmentation 提出了一种新的边界切分定义,包括: 环境、物体、镜头发生变化。 A Benchmark for Multi-shot Temporal Event Localization Temporal Perceiver: A General Architecture for Arbitrary Boundary Detection Progressive Attention on Multi-Level Dense Difference Maps for Generic Event Boundary Detection