搜索到
58
篇与
人工智能炼丹师
的结果
-
 Transformer-based Segmentation Unet系列Transformer模型(医学图像分割) 结合全局(self-attention) 和 局部(Unet) 的特点,构建分割网络 如何在小样本数据集上,使得分割work,有效训练大参数量的transformer模型 Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation [Code] 1. Metric: 2. Motivation: Swin transformer 的优点: 解决长序列问题;窗口内Attention + 窗口间信息交互; UNet的优点: 局部信息, ShortCut 3. Main Contributions: Based on Swin Transformer block, we build a symmetric Encoder-Decoder architecture with skip connections. In the encoder, self-attention from local to global is realized; in the decoder, the global features are up-sampled to the input resolution for corresponding pixel-level segmentation prediction. A patch expanding layer is developed to achieve up-sampling and feature dimension increase without using convolution or interpolation operation. It is found in the experiment that skip connection is also effective for Transformer, so a pure Transformer-based U-shaped Encoder-Decoder architecture with skip connection is finally constructed, named Swin-Unet. 4. Model Structure: 5. Take Home Message: 上采样方式patch expanding layer Medical Transformer: Gated Axial-Attention for Medical Image Segmentation [Code] 主流语义分割Transformer模型 SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers [Code] MaskFormer: Per-Pixel Classification is Not All You Need for Semantic Segmentation [Code]
Transformer-based Segmentation Unet系列Transformer模型(医学图像分割) 结合全局(self-attention) 和 局部(Unet) 的特点,构建分割网络 如何在小样本数据集上,使得分割work,有效训练大参数量的transformer模型 Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation [Code] 1. Metric: 2. Motivation: Swin transformer 的优点: 解决长序列问题;窗口内Attention + 窗口间信息交互; UNet的优点: 局部信息, ShortCut 3. Main Contributions: Based on Swin Transformer block, we build a symmetric Encoder-Decoder architecture with skip connections. In the encoder, self-attention from local to global is realized; in the decoder, the global features are up-sampled to the input resolution for corresponding pixel-level segmentation prediction. A patch expanding layer is developed to achieve up-sampling and feature dimension increase without using convolution or interpolation operation. It is found in the experiment that skip connection is also effective for Transformer, so a pure Transformer-based U-shaped Encoder-Decoder architecture with skip connection is finally constructed, named Swin-Unet. 4. Model Structure: 5. Take Home Message: 上采样方式patch expanding layer Medical Transformer: Gated Axial-Attention for Medical Image Segmentation [Code] 主流语义分割Transformer模型 SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers [Code] MaskFormer: Per-Pixel Classification is Not All You Need for Semantic Segmentation [Code] -
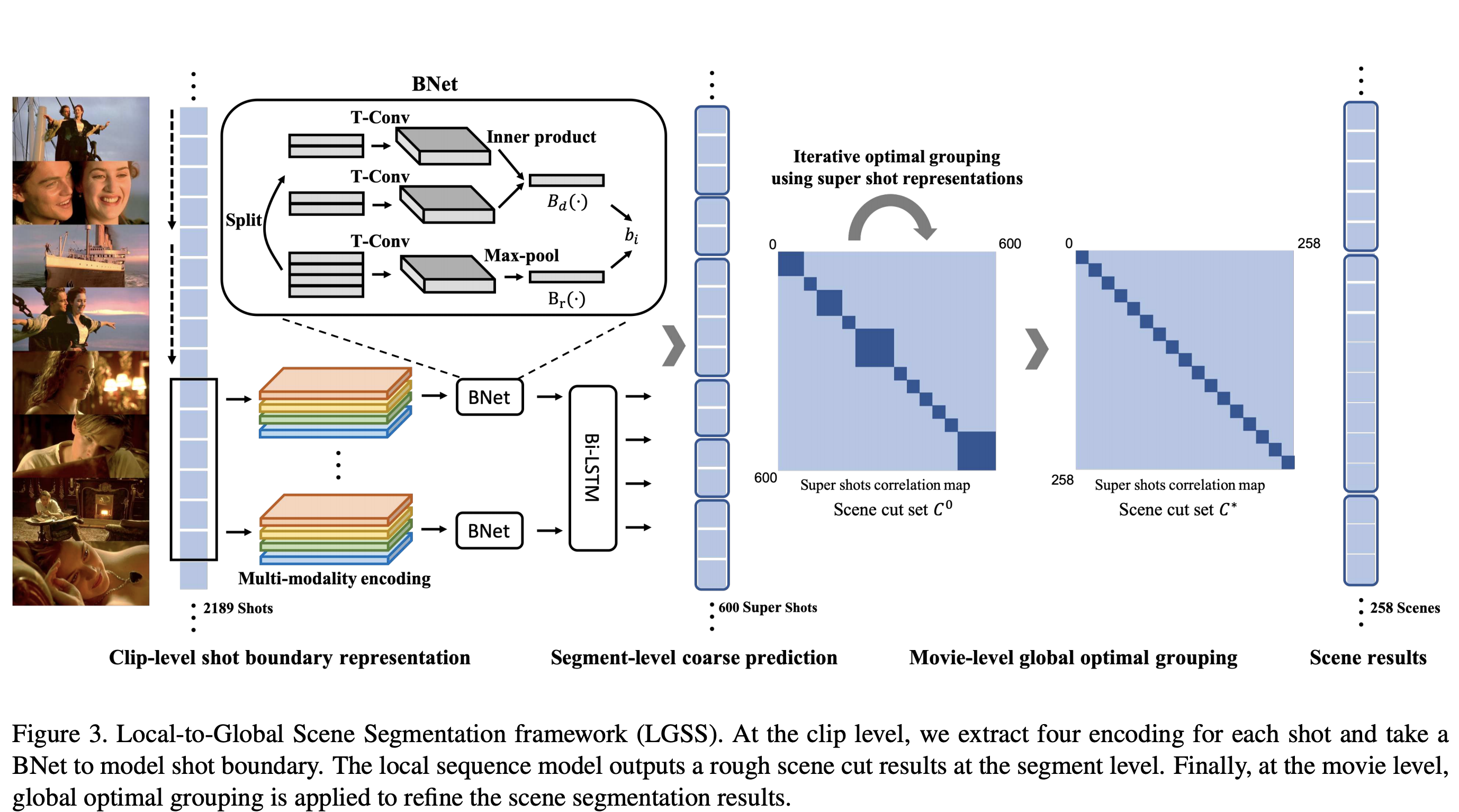
视频时序切分 将视频在时序维度(镜头 + 场景)进行理解, 相关公开数据集和benchmark:SoccerNet-v2、 Kinetics-GEBD、MovieNet ViTT-AACL2020 1. 镜头分割(Shot Boundray Segmentation) 镜头切分benchmark: ClipShots、TRECVID、SoccerNet-v2 1.1 TransNet 1.2 TransNet V2 1.3 DSBD 2. 场景分割(Scene Boundray Segmentation) 2.1 SceneSeg A Local-to-Global Approach to Multi-modal Movie Scene Segmentation [CVPR 2020] 论文简介:提出一个场景切分数据集MovieNet(380个电影),此外提出了一个局部到全局的场景切分算法 Github Code 算法整体流程: 镜头切分,公开的源代码采用了传统方法做镜头切分,可以考虑用深度学习方法做优化,如TransNet等 对每个镜头提取多个模态特征(动作、地点、语音等维度) 进行局部到全局的特征聚合,利用BNet(boundary Network)实现局部的特征融合 a. Clip-level: BNet由两个部分构成: 通过内积建模镜头之间(4个镜头)的差异,通过temporal conv + max pooling建模镜头之间的联系,二者concat b. Segment-level: 通过bi-LSTM实现序列到序列的功能,其中序列长度选取10(远小于镜头数目,为了减少内存消耗) c. global optimal grouping: 通过过动态规划,实现后处理优化(优点:考虑了所有镜头特征,考虑了长时的上下文依赖,缺点: 没有能够实现端到端的优化,与前面的模型时独立的), 具体细节参考StoryGraph 2.2 Shot Type Classification A Unified Framework for Shot Type Classification Based on Subject Centric Lens[ECCV2020] 镜头拍摄风格识别 Deep Relationship Analysis in Video with Multimodal Feature Fusion [ACM MM 2020] 多模态场景理解 2.3 自监督预训练 Shot Contrastive Self-Supervised Learning for Scene Boundary Detection [CVPR2021] Amazon BaSSL: Boundary-aware Self-supervised Learning for Video Scene Segmentation UBoCo : Unsupervised Boundary Contrastive Learning for Generic Event Boundary Detection Scene Consistency Representation Learning for Video Scene Segmentation 3. 事件分割(Event Segmentation) Generic Event Boundary Detection: A Benchmark for Event Segmentation 提出了一种新的边界切分定义,包括: 环境、物体、镜头发生变化。 A Benchmark for Multi-shot Temporal Event Localization Temporal Perceiver: A General Architecture for Arbitrary Boundary Detection Progressive Attention on Multi-Level Dense Difference Maps for Generic Event Boundary Detection
-
Pytorch 常见问题 1.CUDA_VISIBLE_DEVICES设置无效,始终占用GPU0? 1. 在import torch前设置环境变量 2. CUDA_DEVICE_ORDER=PCI_BUS_ID CUDA_VISIBLE_DEVICES=3 python train.py 2.RuntimeError: CUDA error: device-side assert triggered 设置环境变量,让报错显示更具体的代码行 import os os.environ["CUDA_LAUNCH_BLOCKING"] = "1" 3.RuntimeError: DataLoader worker (pid xxx) is killed by signal: Aborted. what(): CUDA error: initialization error pytorch github issue ref google找到的文章,大多怀疑是内存问题 尝试修改pin_memory没有效用 尝试修改shm没有效果,mount -o remount,size=32g /dev/shm 尝试改小num_worker无效果(16->8)将num_workers设置为0可以解决问题,但肯定不是最优解!!! 4.resume training时,出现GPU OOM的问题 在DDP训练场景下进行resume training可能出现该问题,原因在于每个进程torch.load都加载在同一块卡上,导致最后OOM。解决方案: map_location指定加载在哪块卡上 checkpoint = torch.load(checkpoint_path, map_location='cuda:{}'.format(opts.local_rank)) 5.CUDNN和pytorch版本不匹配 可以从torch_stable.html下载安装 6 . unrecognized arguments: --local_rank,由于torch2.0升级导致,修复方案: python -m torch.distributed.launch xxx 替换为 torchrun xxx
-
Shell 常用命令总结 shell常用命令 查看CPU # 总核数 = 物理CPU个数 X 每颗物理CPU的核数 # 总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数 # 查看物理CPU个数 cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l # 查看每个物理CPU中core的个数(即核数) cat /proc/cpuinfo| grep "cpu cores"| uniq # 查看逻辑CPU的个数 cat /proc/cpuinfo| grep "processor"| wc -l # 查看CPU使用情况 mpstat -P ALL 显示目录下文件,按文件大小排序 ls -Shlr #按文件大小(-S)从小到大(-r)排序显示(-hl) 查找文件中包含字符串 cat file.txt|grep -B 2 key # 查找包含key,并显示前两行 cat file.txt|grep -A 2 key # 查找包含key,并显示后两行 cat file.txt|grep -2 key # 查找包含key,并显示前后两行 查找包含字符串的文件: grep -rn "keyword" [files/dir] 查找符合条件的进程并kiil ps aux | grep "python test.py" | awk '{print $2}' | xargs kill -9 #适用于批量删除进程 查看硬盘占用情况 du -hs dir_name # h(human readable) s (而不列出子目录) df -h #列出文件系统的整体磁盘使用量 判断符合条件的文件是否存在 test -f 多线程下载数据 axel -n num_threads -q download_url rync+sshpass免密码同步数据 * rsync -av -e "sshpass -p [your_password] ssh -p [your_port]" src_path dst_path --exclude=exclude_pattern --include=include_pattern` rysnc 同步文件 rsync -avh --progress source_directory destination_directory 定时服务 `30 23 * * * find /data/home/jefxiong/PenguinID/videos/* -mtime +8 -exec rm {} \;` #每天23:00定时删除超过8天的数据 shm 不足 mount -o remount,size=32g /dev/shm mount 解决git无法加入软连接问题 mount --bind src dst 按规则删除指定文件命令 find . -name '*.DS_Store' -type f -delete #删除Mac下.DS文件 find . -name "*" -type f -size 0c | xargs -n 1 rm -f #删除空文件 find . -size 1k -exec rm {} \; #删除小于1k数据 按规则移动文件命令 find . -iname *.npy -exec mv {} dst_dir \; #移动numpy文件到指定目录下 多个python版本共用时,在脚本中指定python PYTHON=${PYTHON:-python} #PYTHON默认值为python,可以在命令行前设置为其他覆盖 #e.g. PYTHON=python3 (bash scripts/xxx.sh, 脚本中用$PYTHON替代 python awk awk '{print $1}' input.txt > out.txt #取input.txt 文件第一列保存到output.txt中 awk '{print $1,$2}' input.txt > out.txt #取input.txt 文件第一列和第二列保存到output.txt中 cat input.txt|awk '{sum+=$1} END {print "Average = ", sum/NR}' #求平均值 cat input.txt|awk '{sum+=$1} END {print "Sum = ", sum}' #求和 awk -F '[|]' '{print $1}' file.txt # 对fil.txt文件利用|进行分割,并取第1个元素输出 # awk 处理字符串: https://www.jianshu.com/p/8cb01a334527 批量加后缀、前缀重命名 for file in ./* ; do mv "$file" "$(basename "$file").mp4"; done; #批量加后缀名.mp4 删除特殊字符文件 # 1. 文件名为 a&b.c, 通过转义\和""解决 rm a\&b.c rm "a&b.c" # 2. 文件名为 -ab.c,通过加入参数-- rm -- -ab.c shell 编程 for i in ${list[@]}; do ... ; done for i in ${list[*]}; do ... ; done for i in exp1 exp2; do ... ; done for i in $(seq 1 100); do ...;done for((i=1; i<100; i++)); do ... ; done # c-like list=(12 34 56) echo ${#list[@]} # 获取数组大小 echo $# #获取执行命令参数个数 免密登陆 # 生成密钥对(若未生成过) ssh-keygen -t rsa -b 4096 # 复制公钥到远程服务器 ssh-copy-id -p {ssh_port} {remote_host} git免密 git config --global credential.helper store 丢弃本地更改,同步远程 git checkout master_leo git fetch origin git reset --hard origin/master_leo
-
Python 工具库使用 用 magic vs filetype 实现视频类型判断 magic 比filetype更好用,能判断更多的类型,能够直接从文件buffer中判断 import magic # pip install python-magic import filetype # pip install filetype src_file = "x.some" print(filetype.guess(src_file)) print(magic.from_file(src_file, mime=True)) print(magic.from_buffer(open(src_file, 'rb'), mime=True)) jupyterlab IDE 函数定义跳转工具 jupyterlab-lsp parallel_apply[依赖pandarallel库] 对于多CPU机器,加速DataFrame的apply方法 安装python包,不更新其他依赖[--no-dependencies] pip3 install torch-fidelity --no-dependencies
-
数据结构/算法学习之LeetCode 数据结构 链表/树 典型链表/树问题 大数相加 反转链表 前序,中序,后序: 递归和迭代的遍历方式 平衡二叉树 二叉搜索树 树/链表参考文章 花花酱-树/链表 字符串 典型字符串问题 KMP Edit Distance 堆栈 典型堆栈问题 前缀表达式 利用栈的迭代解法 队列 典型队列问题 BFS 优先队列(heap) 图 典型图问题 DFS/BFS 最短路径 最小生成树(Kruskal, Prim两种算法) 图参考文章 花花酱-图 算法 查找 二分查找、哈希查找、常用set/map 排序 O(n^2)与O(nlogn)的排序算法,特点、冒泡/选择/插入,归并/快排/堆排序 回溯法 排列、组合 BFS/DFS 动态规划/贪心算法 从递归到动态规划 暴力解,复杂度: 指数级别时间复杂度 定义状态函数, 写状态转移方程(最优子结构)--递归实现: 指数级别时间复杂度 记忆化搜索: 递归实现 + 记忆化搜索 (自顶而下的方法): 多项式级别时间复杂度 自底而上求解--动态规划: 多项式级别时间复杂度 优化空间复杂度(例如对索引%2,只保留两行数据) 典型动态规划问题 斐波那序列 爬台阶 0-1背包问题/(无限使用背包问题,多维约束,物品依赖与排斥) 最长上升子序列: 动态规划时间复杂度$O(n^2)$ 最长公共子序列 单源最短路径算法 动态规划参考文章 花花酱-贪心/动态规划 参考链接 花花酱B站视频 拉钩+leetcode培训视频 geeksforgeeks 数据结构 Leetcode All in One 编程之法:面试和算法心得
-
流畅的Python笔记 以代码和注释方式,记录《流畅的Python》的笔记,持续更新 第一章 Python的数据类型 魔术方法(magic methods)是形式为"xxx()"的函数为Python的内置函数,用于实现一些特定的功能 用魔术方法实现可迭代对象 class MyList(): """ 通过实现'__getitem__()'和'__len__()' 完成 """ def __init__(self): self.data = range(0,100) def __getitem__(self, index): """ 实现该方法之后,对象变成可迭代和切片,e.g. print(MyList()[0]) for x in MyList(): print(x) """ return self.data[index] def __len__(self): """ 实现该方法之后,可以用len求对象的长度,e.g. len(MyList()) """ return len(self.data) 用魔术方法实现运算符重载 class Vector(): def __init__(self, x, y): self.x = x self.y = y def __repr__(self): """在print 对象的时候的输出格式, 如果没有__repr__方法定义,会输出对象在内存中的地址 """ return "{}(x = {}, y = {})".format(self.__class__.__name__, self.x, self.y) def __add__(self, vector): """ 重载加法+运算符 """ x = self.x + vector.x y = self.y + vector.y return Vector(x, y) def __mul__(self, scalar): """ 重载乘法*运算符 """ return Vector(self.x * scalar, self.y * scalar) print(Vector(1,2)) #Vector(x = 1, y = 2) print(Vector(1,2) + Vector(3,4)) #Vector(x = 4, y = 6) print(Vector(1,2)*0.5) #Vector(x = 0.5, y = 1.0) 第二章 序列构成的数组 两种生成序列的方法 # 利用生成器生成的序列(元组构建生成器)可以节约内存,不会在内存中创建所有需要的元素,当列表长度过长时,优先选择生成器方式 x_generator = (i for i in range(10000000)) # 生成器,type(x_generator)=<class 'generator'> x_list = [i for i in range(10000000)] # 列表, type(x_list)=<class 'list'> 利用list[::-1]实现反转的原理 列表切片的常规用法,list[start:end:stride], list[::-1]省略了前两个,-1表示取值的步长,因此可以实现列表反转的功能 利用count实现列表/元组计数 l = [1, 1, 2, 3] t = (1, 1, 2, 3) print({x:l.count(x) for x in set(l)}) print({x:t.count(x) for x in set(t)}) 对比 list、tuple、queue、deque(collections) # TODO 第三章 字典和集合 几种不同的dict from collections import defaultdict from collections import OrderDict # {} 内置字典 # OrderDict 是有序字典 # defaultdict #当key不在字段内,默认构建初始值 dict/set vs list 内部维护了散列表,以空间换时间。代码中涉及在大数组中查找key时,可以考虑为dict实现。
-
-
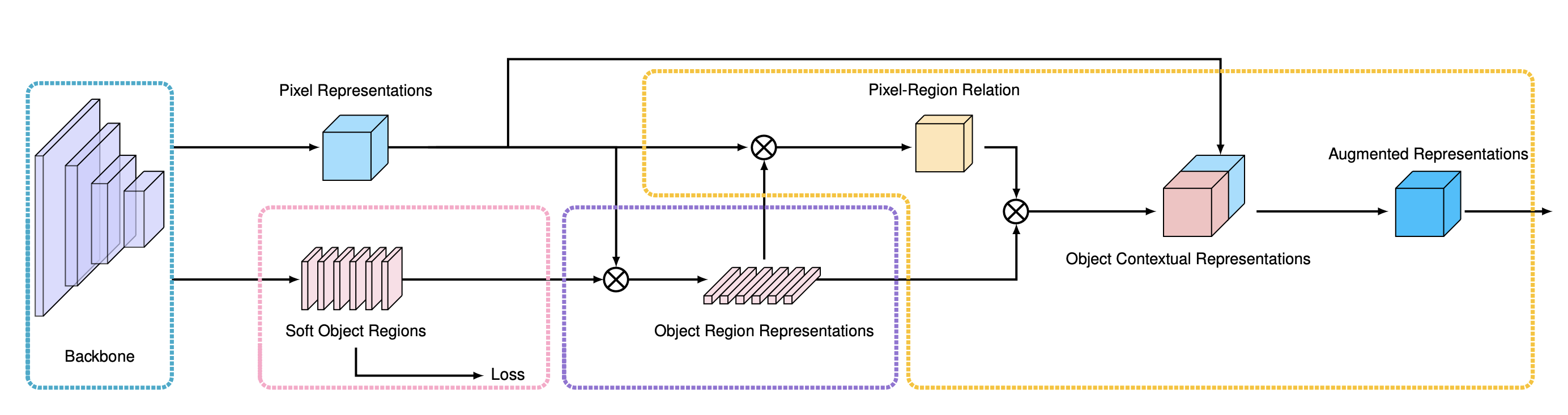
Awesome Segmentation 本文对截止到2020年各大顶会的分割论文,包括语义分割,实例分割, 全景分割,视频分割等领域发展进行小结,不定期更新。 Awesome Semantic Segmentation CVPR 2020 StripPooling Strip Pooling: Rethinking Spatial Pooling for Scene Parsing [Paper] [Code] ECCV 2020 Error-Correcting Supervision Semi-Supervised Segmentation based on Error-Correcting Supervision [Paper] Segmentation Failures Detection Synthesize then Compare: Detecting Failures and Anomalies for Semantic Segmentation [Paper] OCRNet Object-Contextual Representations for Semantic Segmentation[Paper] [Code] coarse2fine、attention IFVD Intra-class Feature Variation Distillation for Semantic Segmentation [Paper] [Code] 模型蒸馏 CaC-Netx Learning to Predict Context-adaptive Convolution for Semantic Segmentation[Paper] [[Code]()] 通过预测卷积kernel进行空间attention TGM Tensor Low-Rank Reconstruction for Semantic Segmentation [Paper] [Code] non-local方法的改进 Segfix SegFix: Model-Agnostic Boundary Refinement for Segmentation [Paper] Motivation: 边缘处的点的类别与“内部”的点的类比相似,通过网络学习shift DecoupleSegNets Improving Semantic Segmentation via Decoupled Body and Edge Supervision [Paper] [Code] 将主体和边缘特征分离,多任务学习 EfficientFCN EfficientFCN: Holistically-guided Decoding for Semantic Segmentation [Paper] Motivation: 如何高效率地扩充特征的感受野 算法原理:通过采用减小stride+dilated conv的方式的方式,由于特征分辨率增加导致计算量暴增。文章主要提出一种利用stride=32生成“Codebook”,可以理解为不同patten的特征集合,利用stride=8的特征生成集合的组合系数,实现“上采样” GCSeg Class-wise Dynamic Graph Convolution for Semantic Segmentation [Paper] 图卷积做全局特征提取 CVPR 2019 Fast Interactive Object Annotation with Curve-GCN. [Paper] [Code(pytorch)] 利用Graph Convolutional Network (GCN) 预测多边形的各个端点实现分割标注 Large-scale interactive object segmentation with human annotators. [Paper] 交互式分割 Knowledge Adaptation for Efficient Semantic Segmentation. [Paper] 通过知识蒸馏实现大降采样(分辨率降16倍)的高效率分割 通过autoencoder对Teacher网络的特征进行压缩去噪,用L2损失比较T的编码特征与S的编码特征 两两像素之间的相似性的差异(pair-wise distillation) Structured Knowledge Distillation for Semantic Segmentation. [Paper] 通过知识蒸馏实现高效分割,引入多个约束项 单个像素的损失(Teacher与Student之间逐像素损失,Student与GT之间逐像素损失) Teacher与Student网络中两两像素之间的相似性的差异(pair-wise distillation) 利用判别网络实现约束Embedding的相似性(holistic distillation) FickleNet: Weakly and Semi-supervised Semantic Image Segmentation using Stochastic Inference. [Paper] 图片类别标注(Weakly); 图片类别标注+部分逐像素标注(Semi-supervised) Dual Attention Network for Scene Segmentation. [Paper] [Code(pytorch)] 加入空间上(二阶关系,借鉴Non-Local)和通道上的注意力 [DUpsampling]: Decoders Matter for Semantic Segmentation: Data-Dependent Decoding Enables Flexible Feature Aggregation. [Paper] 基于Encoder-Decoder的算法通常为了避免Encoder的最后一层卷积层空间分辨率过小,Encoder网络的total_stride会尽可能小(多数为8),导致占内存,消耗大量计算资源 该论文提出的DUpsampling,利用分割标注在空间上的冗余性(对标注概率label_prob的压缩,对低分辨率网络输出pred_prob,重建高分辨率标注概率label_prob)提出了一种Data-Dependent的上采样方法,比转置卷积上采样方法参数量少,比双线性插值方法更好。 得益于DUpsampling,可以将特征分辨率将到足够低,并对底层特征进行Downsample,然后与低分辨率高层特征融合,减少计算量 In Defense of Pre-trained ImageNet Architectures for Real-time Semantic Segmentation of Road-driving Images. [Paper] [Code(Pytorch)] 出发点: 实现实时语义分割 轻量化backbone: compact encoders(ResNet18 or MobileNet V2) 轻量化decoder with lateral skip-connections(UNet类似结构) 增大网络的感受野:SPP(PSPNet) 或 结合lateral skip-connections的图像金字塔结构,有利于识别大目标 ECCV 2018 [ICNet]: ICNet for Real-Time Semantic Segmentation on High-Resolution Images. [Paper] [Code(Tensorflow)] PSPNet(~1FPS)的加速版本,能够达到实时,30FPS; Image Cascade Network(ICNet) 为什么不直接在最后一个分辨率下,实现1/16和1/32的降采样,然后多尺度特征图融合(UNet结构),再加上多个尺度上的监督,也就是DeepLabV3+的简化模型版本? [ExFuse]: Enhancing Feature Fusion for Semantic Segmentation(Face++).[Paper] semantic supervision(SS): 在backbone的预训练的过程,在网络的中间层加入多个分类损失,使得中间层带有更多的语义信息 layer rearrangement(LR): 调整backbone中不同block的通道数的分布,使得深层和浅层具有相近的通道数,即丰富底层特征,有利于后续步骤中深层和浅层的融合 explicit channel resolution embedding(ECRE):借鉴超分辨率中的上采样方式(sub-pixel Upsample) semantic embedding branch(SEB): 将不同深层特征进行上采样,然后与浅层特征相乘融合 densely adjacent prediction(DEP): 可以理解为卷积核为$k \times k$固定参数$\frac{1}{k \times k}$的group conv [DeepLabv3+]: Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. Adaptive Affinity Fields for Semantic Segmentation [PSANet]: Point-wise Spatial Attention Network for Scene Parsing [ESPNet]: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation [BiSeNet]: Bilateral Segmentation Network for Real-time Semantic Segmentation CVPR 2018 [DFN]: Learning a Discriminative Feature Network for Semantic Segmentation(Face++). [Paper] [Code(tensorflow)] The Lovász-Softmax loss:A tractable surrogate for the optimization of the intersection-over-union measure in neural networks. [Paper] [Code] [EncNet]: Context Encoding for Semantic Segmentation Context Contrasted Feature and Gated Multi-Scale Aggregation for Scene Segmentation DenseASPP for Semantic Segmentation in Street Scenes Dense Decoder Shortcut Connections for Single-Pass Semantic Segmentation Awesome Instance Segmentation Latest YOLACT:Real-time Instance Segmentation. [Paper] CVPR 2020 BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation GITHUB CODE PolarMask: Single Shot Instance Segmentation with Polar Representation GITHUB CODE CVPR 2019 Hybrid Task Cascade for Instance Segmentation. [Paper] [Code(pytorch)] Mask Scoring R-CNN. [Paper] 算法简介:Mask Scoring R-CNN是对Mask-RCNN的改进,文章的出发点在于mask-rcnn采用分类的得分作为检测结果和分割结果与GT重合程度的得分,但是在实际应用中常常出现,分类得分高,但是检测结果和分割结果并不好的问题。为了更准确的评估分割结果的好坏,文章在Mask-RCNN的基础上提出一个MaskIOU分支,该分支以ROI区域的分割Mask和ROIAlign的特征作为输入,预测输出该ROI predicted mask与GT mask 之间的IOU score。结合IOU score 和classification score,判断该ROI输出mask的精确程度 值得借鉴的点: CVPR 2018 Path Aggregation Network for Instance Segmentation. [Paper] [Code(pytorch)] COCO2017 Winner :fire: Masklab: Instance segmentation by refining object detection with semantic and direction features ICCV 2017 Mask R-CNN. [Paper] CVPR 2017 End-to-End Instance Segmentation with Recurrent Attention.[Paper] ECCV 2016 Instance-sensitive fully convolutional networks Awesome Panoptic Segmentation CVPR 2019 Panoptic Segmentation. [Paper] Learning to Fuse Things and Stuff. [Paper] Attention-guided Unified Network for Panoptic Segmentation. Panoptic Feature Pyramid Networks. UPSNet: A Unified Panoptic Segmentation Network DeeperLab: Single-Shot Image Parser An End-to-End Network for Panoptic Segmentation PanopticFusion: Online Volumetric Semantic Mapping at the Level of Stuff and Things Awesome Video Object Segmentation 视频分割 VS 语义图片分割: 相邻帧得到相似的结果(时间冗余度和视觉抖动) VOS Performance(mean region similarity) Algorithm DAVIS(16val/17) YouTube-VOS Youtube-Obj(mIOU) Speed(FPS) RVOS(CVPR19) -/48.0 - - 22.7 STCNN(CVPR19) 83.8/58.7 - 79.6 0.256 FEELOVS(CVPR19) 81.1/- 1.96 SiamMask(CVPR19) 35 FAVOS(CVPR18) -/54.6 - - - OSVOS(CVPR17) 79.8/56.6 - - 0.1~5 MaskTrack(CVPR17) 80.3/- - 71.7 <1.0 OnAVOS(BMVC17) 86.1/- CVPR 2019 RVOS: End-to-End Recurrent Network for Video Object Segmentation. [Paper] [Code(pytorch)] 特点: 多目标视频分割;one-shot and zero-shot VOS spatial(Instance) and temporal(video) Recurrent Netorrk STCNN: Spatiotemporal CNN for Video Object Segmentation. [Paper] [Code(pytorch)] 主要由两个支路构成,Temporal Coherence Branch ,利用GAN进行无监督的预训练(输入前4帧, 预测输出当前帧, 生成器的目标为最小化生成图片与当前帧的MSE和最大化判别器的损失),网络的目的是学习时序的一致性;另外一条支路为Spatial Segmentation Branch,融合当前帧和历史帧的多尺度特征,得到当前帧的预测结果 FEELOVS: Fast End-to-End Embedding Learning for Video Object Segmentation. [Google] [Paper] [Code(tensorflow)] SiamMask: Fast Online Object Tracking and Segmentation: A Unifying Approach. [Paper] [Code(Pytorch)] MHP-VOS: Multiple Hypotheses Propagation for Video Object Segmentation. [Paper] 解决目标被遮挡或消失 Accel: A Corrective Fusion Network for Efficient Semantic Segmentation on Video. [Paper] A Generative Appearance Model for End-To-End Video Object Segmentation. [Paper] [Code(Pytorch)] ECCV 2018 YouTube-VOS: Sequence-to-Sequence Video Object Segmentation. [Paper] [DatasetURL] Video object segmentation with joint re-identification and attention-aware mask propagation CVPR 2018 Motion-guided cascaded refinement network for video object segmentation. FAVOS: Fast and accurate online video object segmentation via tracking parts. Efficient video object segmentation via network modulation. CVPR 2017 OSVOS 可以认为是将语义分割方法适用到视频目标分割最直接的方法,由离线训练二分类网络(物体分割)+在线finetune构成。FusionSeg和MaskTrack用了光流信息和RGB输入图像进行互补,通过在网络的输入中加入传统方法计算的光流。FusionSeg的光流支路进行重新训练,和MaskTrack 直接沿用RGB支路的模型,前者的光流支路结果通过可学习的1*1卷积进行融合,而后者直接将光流支路得到的结果叠加求平均。 OSVOS: One-Shot Video Object Segmentation.[Paper] [Code(pytorch)] [Code(TensorFlow)] 算法流程图:ImageNet预训练+视频分割数据集DAVIS二分类训练+在线测试Finetune 特点:单帧处理,没有累计误差;通过Finetune+物体边缘损失约束,用时间换准确率 FusionSeg: Learning to combine motion and appearance for fully automatic segmentation of generic objects in videos.[Paper] [Code(caffe)] 利用外观信息和运动信息构成two stream结构,实现视频目标分割 利用光流信息和当前帧的图像作为输入,够成two-stream结构,实现信息互补:ResNet101结构;最后采用不同大小的空洞卷积构成多尺度,最后通过逐点求极大值进行多分支结果融合。网络训练通过将不同分支分开单独训练后,再训练最后的融合层(1*1) 为了解决视频目标分割数据集不足的问题,提出利用预训练分割模型(VOC2012)+视频目标检测数据集(ImageNet VID)标注框进行筛选,再后处理得到训练数据,过程如下图: 缺点:光流采用传统方法估计得到,得到的带有噪声的光流输入图像可能使得训练不稳定,且会影响最后的输出结果 MaskTrack: Learning video object segmentation from static images. [Paper] [Code] 利用前一帧预测的mask和当前RGB图像作为输入,mask(t-1)指示了目标的位置,形状大小。训练通过对单张图像进行平移,形变生成训练数据图像对(RGBImg,mask);离线训练(静态图片平移形变生成的数据优于视频数据集,文中采用显著性检测数据集)+在线Finetue;此外可以加入光流信息互补提升性能,将RGB图像用光流图像替代,经过同样的卷积网络,得到输出概率与MaskTrack的输出概率得分进行平均(论文3.3节中) 特点: 速度慢(Finetune+光流计算耗时);前一帧的输入图像可以是粗糙的因此可以用目标检测算法相结合 Others OnAVOS: Online adaptation of convolutional neural networks for video object segmentation. [BMVC17] Awesome Video Instance Segmentation Reference Awesome-Panoptic-Segmentation Awesome Semantic Segmentation InstanceSegmentation 漫谈全景分割 视频分割在移动端的算法进展综述 Segmentation.X Deep-Learning-Semantic-Segmentation 自动驾驶入门日记-5-视频语义分割 ECCV2020 segmentation
-
-
-